Week_2 Optimization, 중요한 개념
Optimization , 최적화는 convex optimization, gradient-free optimization 등등 분야가 굉장히 많다.
각각 한학기는 잡고 깊게 팔만한 내용이지만, 핵심만 추려서 정리해보겠다.
Important Concepts in Optimization _ 확실히 짚고 넘어가야하는 개념 ⭐️⭐️
1. Gradient Descent : First-order iterative optimization algorithm for finding a local minimum of a differentiable function
<정의>
Loss function, 손실 함수에 대해 1차 편미분을 해서 구한 Gradient에 learning_rate를 곱한값을 parameter(ex.Weight, bias)에서 빼주면서 업데이트 하는 최적화 방법.
≫ 한마디로, 시작점에서부터 최저점까지 갈때까지 최저점이 있을 방향으로 찔끔찔끔 움직인다. (방향을 정하기 위해 미분을 한다.)
하지만 이런 경우는 목표에 도달하기도 전에 local minima에 빠질 수 있다 == 가다가 정신팔릴 확률이 다분하다.
2. Generalization : 일반화
<정의>
네트워크의 성능이 학습데이터에서 보인 성능만큼 unseen data에서도 나올수록 일반화가 잘 되었다.
≫ 딥러닝 모델은 일반화가 가능해야된다고들 한다.
일반화는 학습데이터와 unseen 데이터의 차이를 줄여야 하기 때문에 나온 개념이다.
차이에 중점을 두기 때문에, 만약 학습데이터의 성능이 별로면 일반화가 잘됐다고 헤봤다 의미가 없다. 테스트 데이터의 성능도 구리다는 소리밖에 안된다.
3. Underfitting vs. Overfitting
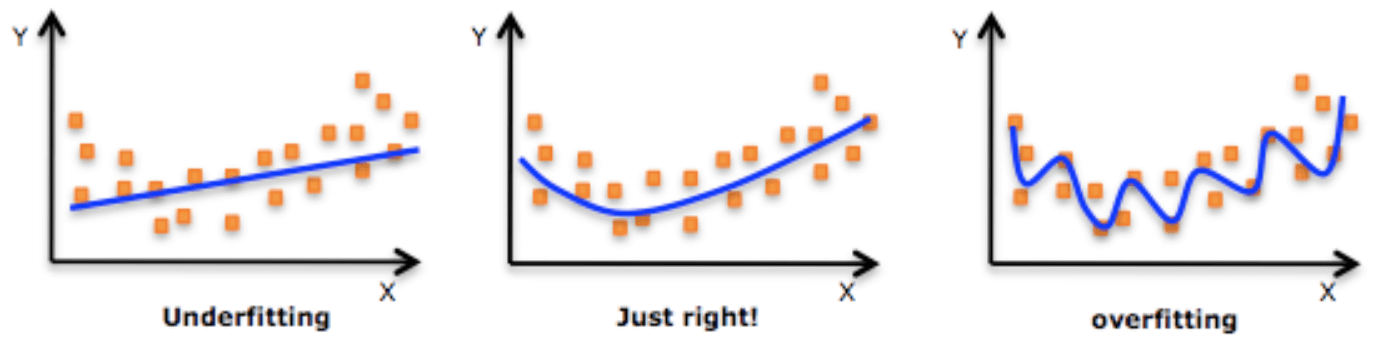
Underfillting 과소적합, Overfitting 과대 적합, 그리고 그 중간 어딘가에 sweet spot을 찾는게 딥러닝의 목표다.
Underfitting은 주로 두가지 이유로 발생한다. 네트워크가 너무 간단해서 모델이 세부적인 현상을 구현하지 못하는 경우. or 학습이 덜된 상태여서 데이터를 잘 나태내지 못하는 경우이다.
Overfirring은 학습데이터에는 잘 동작하지만 test데이터에는 잘 동작하지 않는, 일반화가 잘 안된 케이스를 의미한다.
가령 자동차 이미지를 학습시키는데 data 1000개중 모두 자동차 옆면사진일때, 자동차 앞면사진이 주어졌을때 자동차라고 인지하지 못한다.
4. Cross-validation
데이터는 일반적으로 train : test = 8:2로 구성이 된다. 이때 test data는 오직!! 성능 검사에만 사용이 된다.
그래서 validation set라는게 등장했는다. train : val : test = 6 : 2 : 2로 validation set은 train set에서 임의로 선택해서 중간검증에 사용된다. validation set에 대한 모델의 추론 결과를 보고 hyperparameter같은것을 직접 튜닝할 수 있게 해 주는 검증데이터이다.

최종 성능 평가를 위한 test 이전에 validation으로 어떤 모델을 어떤 epoch로 학습시킬때
unseen data에 대해서 좋은 성능을 보이는지 파악할 수 있게 돕는다.
5. Bias and Variance
Bias 는 치우친 정도를 의미하고 Variance는 퍼져있는 정도를 의미한다.

두 지표 사이에는 tradeoff가 존재하는데,

딥러닝의 cost를 줄이는 방향으로 학습을 진행한다 했을때, cost는 bias , variance , noise 세개 부분으로 나눠서 생각할 수 있다.
Noise가 있는 모델이라는 가정하에 bias 를 줄이면 variance가 올라가고, variance가 줄어들면 bias가 심해진다.
6. Bootstrapping
: any test or metric that uses random sampling with replacement
≫ 학습 data가 고정되어 있을때 subsampling을 이용해 여러개의 train sata를 만든다. 각각의 train data가 개별적인 모델/metric에 적용된다.
7. Bagging vs. Boosting

Bagging ≫ 학습데이터 여러묶음으로 subsmapling -> 여러 독립적인 모델 생성 -> 모델들의 결과 평균내어 output 구함
Boosting ≫ 학습데이터 n개가 있을때 1~n까지 sequential 하게 바라보며 성능이 낮거나 까다로운 데이터셋을 골라내고 각각 학습시킴.
여러개의 weak model이 만들어지고, 그들의 weight를 조합해 하나의 strong model 생성