Week 11/12/13 - Semantic Segmentation - DeepLab v1
이번 포스팅에서는 DeepLab version 1에 대해 살펴보겠다.
Receptive Field를 확장시킨 모델

Receptive Field란 하나의 뉴런이 얼마만큼의 정보를 바라봤는지를 나타낸다.
Convolution을 진행하다 보면 레이어가 점차 깊어질수록 activation map의 한 점에 영향을 주는 Pixel들이 점차 많아진다.
이를 좀 더 직관적으로 보면,

A,B,C 모두 같은 새를 바라보고 있다.
A,C 와 B로 그림을 나눠볼 수 있다. 기준은 뭘까?
바로 B는 몸통을 집중적으로 보고 있고 A와 C는 새의 전반적인 정보를 모두 포함한다는 것이다.
B와 C를 비교했을때는, 컴퓨터 입장에서 B를 새라고 인식하기 보다 C를 새라고 인식하기 더 수월할 것이다.
-> 즉, receptive field( 얼마만큼의 영역을 보고 있느냐)가 segmentation에 끼치는 영향은 매우 크다.

왼쪽터럼 receptive field가 너무 작을때는 버스를 통으로 인식하지 못하고 왼쪽과 같이 여러개로 분산이 되는 문제점이 발생한다.
그래서 이 Receptive Field를 넓혀서 context를 잘 파악하고자 한게 Deep Lab이다.
이미지의 크기는 많이 줄이지 않고 파라미터의 수도 변함이 없는 채로 Recptive Field만 넓게 하는 방식이 없을까?
-> Dilated Convolution

input이미지에서 더 sparse하게 정보를 가져 온다.
일반 conv보다 더 큰 receptive field이지민 output은 그대로 3x3인 효과가 있다. Parameter수도 동일
DeepLab에서 적용한 또하나의 주요 기술은 CRF이다.
Dense Conditional Random Field

모델의 결과에 후처리를 하는 개념으로, 다소 blurry한 결과를 깔끔하고 정교하게 정리해준다.

기본적으로 heatmap은 왼쪽과 같이 추출이 된다. 확률을 표현하기 때문에 경계선이 뚜렷하지 않다는 특징이 있다.
이 확률맵과 원본 이미지를 또 하나의 딥러닝 모델에 넣고, Ground Truth로는 정답레이블을 줘 또 하나의 모댈을 훈련시키는 게 CRF의 원리이다.
복잡한 모델이기 때문에 다 이해하진 못했고, 원리를 간단히 설명하자면,
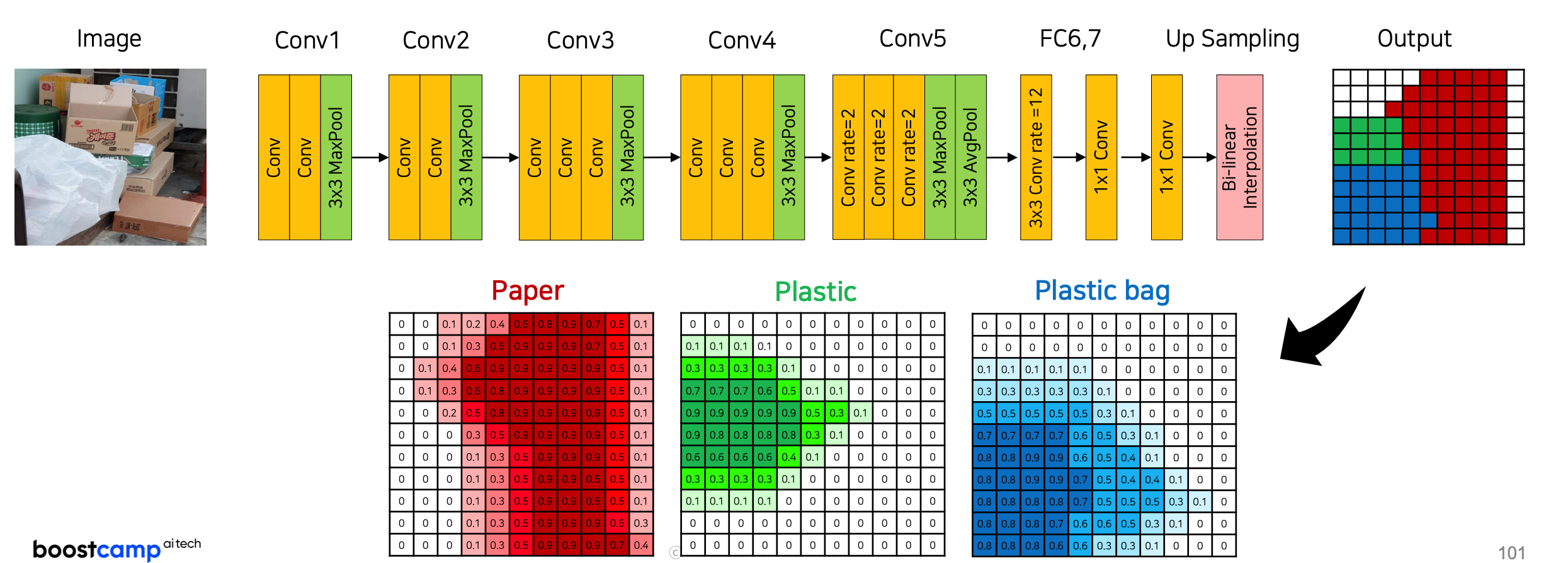
위와 같이 각각의 class에 대한 확률 결과값이 있을떄, 색상이(class)가 유사한 픽셀이 가까이에 위치하면 같은 범주에 속하고,
색샅이 유사하더라고 픽셀의 거리가 멀면 같은 범주에 속하지 않는 원리에 입각해 학습을 한다.
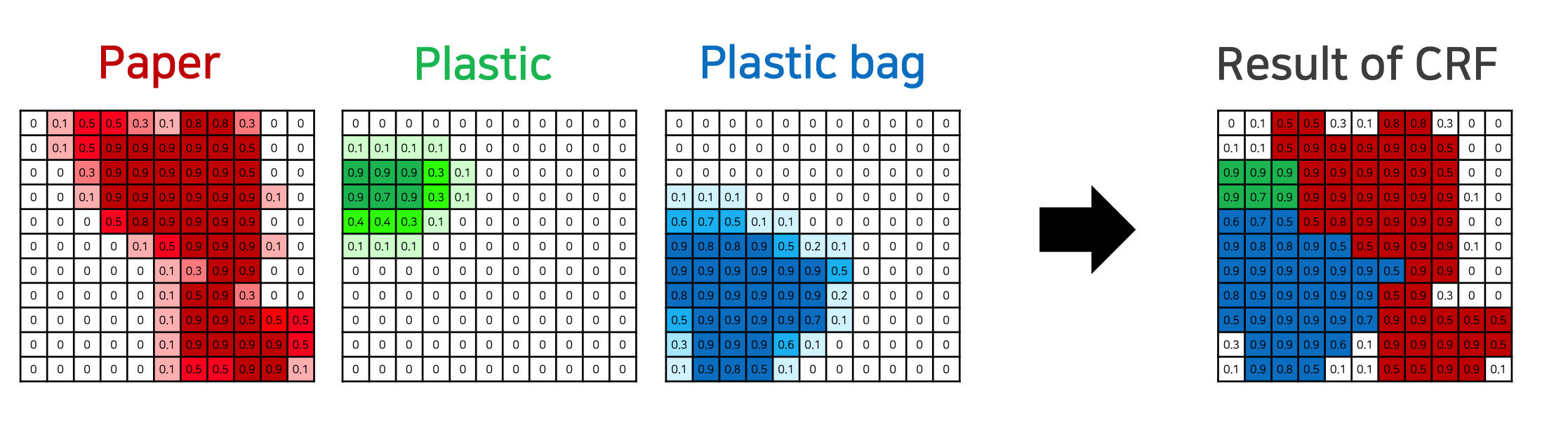
최종적으로 각 픽셀별 가장 높은 확률을 갖는 카테고리를 선정해 최종 결과를 도출한다.