오늘은 Microsoft에서 발표한 GLIP : Grounded Language Image Pretraining(2021) 논문을 정리해보도록 하겠습니다.
글 중간중간 논문에 나오지 않은 제 생각과 정보가 들어가 있으니 틀린게 있다면 언제든지 알려주시길 바랍니다.
**
vision-language multimodal의 근본논문 중 하나인 CLIP과 이름이 상당히 유사합니다.
실제로도 CLIP을 기반으로 아이디에이션한 논문입니다.
GLIP의 주요 contribution은 Image Level -> Instance Level에 있다고 생각합니다.
그럼 논문의 흐름을따라 내용을 정리를 시작해보겠습니다.

1. Introduction
2개 이상의 modality를 사용하면, 각각의 modality로 부터 얻은 representation을 합쳐, 더 큰 폭의 representation understanding이 가능해진다. =multimodal이 성행하는 이유.
CLIP도 vision 과 language를 결합해 open vocabulary, 즉 미리 정의된 label set에 구애되지 않고 classification을 할 수 있게 했다.
그렇다면 GLIP은 어떤 방식으로 multimodal phrase grounding을 했나?
MAIN Contribution
1. Unifying detection and grounding* by reformulating and object detection as phrase grounding
- 기존의 detection task에서 image만을 input으로 받는거에 반해, text(phrase, 문장)을 함께 입력해준다.
이 text는 possible categories후보들을 포함하고 있다.
- CLIP과는 다르게 vision - language fusion을 early stage부터 진행한다.
*Phrase Grounding : 한 문장에서 특정 구문이 이미지상 어디에 위치해 있는지 localize하는 task
2. Scaling up visual concepts with massive image-text data
- GLIP을 image-text-bbox data를 가지고 학습한다 -> Teacher Model
- bbox annotation이 빠진 image-text데이터에 pseudo-label을 생성해 Student Model을 학습한다.
방대한 양의 image-text pair를 놓치지 않고 어떻게든 활용할 수 있어진다.
+ Student Model이 Teacher Model을 능가하게 만들 수 있다는 내용도 나오는데, 뒤에 자세히 설명하겠다.
3. Transferlearning with GLIP: one model for all
- Pre-train 과정에서 한번도 본적 없는 dataset에도 뛰어난 성능을 보인다.
- task-specific prompt embedding을 통해서 detection 외의 task에서도 fine tuning가능 -> GLIPv2(2022)의 내용
2. Related Work
skip
3. Grounded Language Image Pre-training
Object Detection과 Phrase Grounding의 concept은 상당히 유사하다.
둘 다 object의 위치를 찾고, semantic한 의미와 연결 짓는다는 점에서 같은 pipeline을 공유할 수 있다고 저자들은 말한다.
3.1에서는 어떤식으로 둘이 같은 pipeline을 사용할 수 있는지 자세하게 설명한다.
3.1 Unified Formulation
= 기존의 Object Detection과 Phrase Grounding task를 하나로 잘 통일 시켰다.
Background: Object Detection Flow
Image -> Encode (CNN, transformer 등) -> extrach region features
-> prediction head (box classifier, box regressor)
실제로 Object Detection과 Phrase Grounding의 loss 계산 구조가 유사하기 때문에 어떤 Detection 모델도 Grounding의 form으로 바꿀수 있다.
가령 기존의 object detection에서 class가 Bird, Car, Dog...이었다면
이를 prompt로 바꿔서 "Detection : Bird. Car. Dog. ~~~~" text ecnoder(Enc_L)에 넣어주기만 하면 된다.

O : Image를 encoding한 결과 vector
W : classifier weight
S_cls : output classification logits
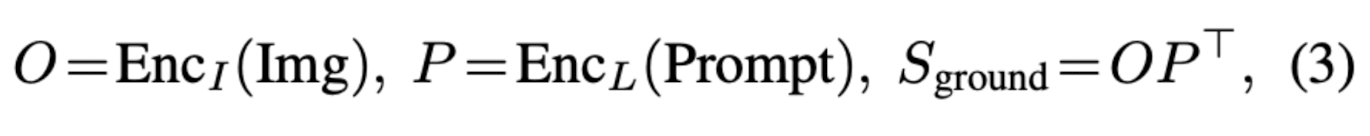
O : Image를 encoding한 결과 vector
P : Text를 encoding한 결과 vector
S_ground : output grounding logits
++ 여기에 따로 localization head를 붙여 localize를 하고, PhraseGrounding classifier 에 들어가는 Img는 Region, O는 Region Feature라는 점을 유의하자.
3.2 Language-Aware Deep Fusion
late fusion models :
대표적인 sample로 CLIP을 들었는데, 아래 그림에서도 알 수 있다 싶이, Text와 Image가 따로 놀고,
따로 인코딩 과정을 거치다가 마지막 logit을 구하는 부분에서만 융합이 된다. (matrix multiplication을 한다)
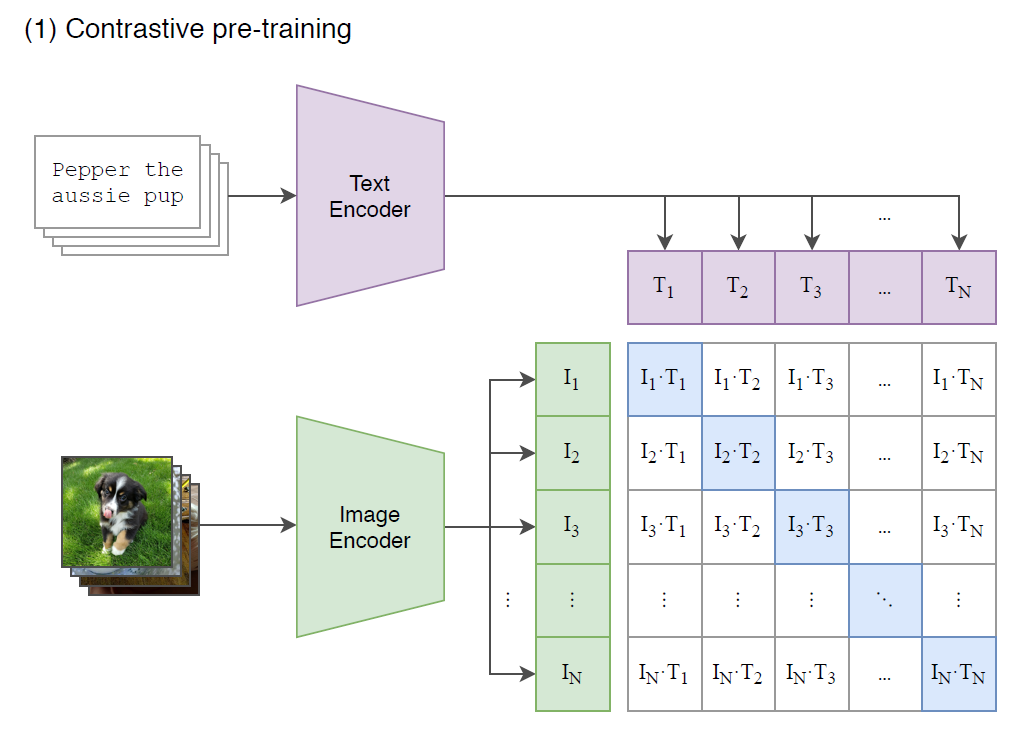
deep fusion models :
이에 반해 GLIP이 채택한 deep fusion model은 text와 image를 encoding하는 과정에서부터 feature를 서로 섞는다.
이를 early-stage fusion이라고 표현한다.

Fusion 방법

(4) X-MHA 는 cross modality multi-head attention module이다. 여기서 각 모달을 fusion해서 각각 seperate한 모달의 feature로 출력후,
(5)(6)은 single modality fusion으로, viz-lang이 fusion된 feature와 single modal feature를 fusion한다.
X-MHA
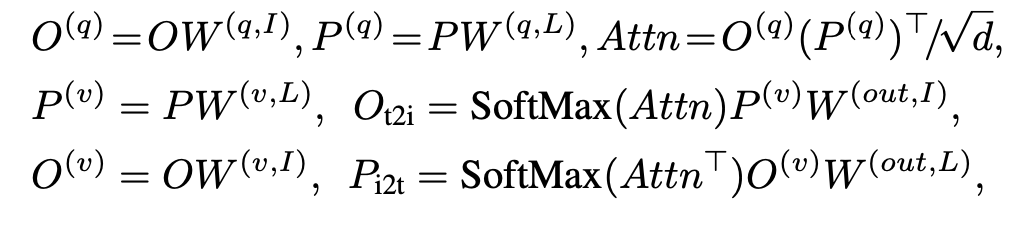
O : vision feature
P : lang feature
3.3. Pre-training with Scalable Semantic-Rich Data
Prior work는 대부분 self-training 방식으로 scale up을 한다.
Teacher model을 학습시키고 knowledge distilation을 통해 student 모델을 학습시키는 대표적인 준지도학습 방식인데,
한계점은 student model은 teacher가 아는것 이상을 배울 수 없다는 점이다.
가령 teacher는 A,B,C밖에 모르는데, student가 갑자기 D를 알 수는 없는 것처럼, 좀 더 정교한 A,B,C에 대해 배울수는 있겠지만 그 이상의 것을 알 수는 없다.
하지만 Grouning Data의 경우는 다르다고 저자는 주장한다.
Student model possibly outperform the teacher model
논문을 읽어보니 굉장히 간단한 컨셉이고 당연한 얘기지만 흥미로운 포인트들 중 하나였는데,
과정부터 설명하자면,
1. Teacher model을 Gold Data로 학습한다.
-> 여기서 말하는 Gold Data란, (human-annotated) Grounding Data + Detection Data
2. Trained Teacher Model을 web collected image-text data에 inference, pseudo label data 생성.
3. Student model은 Gold Data + Pseudo label data로 학습.
보편적인 Teacher-Student모델과 다를게 없어보이는데, Data의 특성에서 차이를 보인다.
논문의 예시를 들어 설명해보겠다.

Gold Data로 학습된 Teacher Model T는 왼쪽 그림의 image-text data를 pseudo labeling하려고 한다.
근데 T는 vaccine이 뭔지 배우지 않았다. 처음 알게 된 단어다. 하지만 풍부한 Gold data덕분에 small vial은 뭔지 알고 있었다.
그럼 이미 아는 사실을 기반으로 educated guess가 가능해진다.
'a small vial of vaccine'은 하나의 세트이기 때문에 vial을 localize하면 vaccine도 같이 localize된다.
이렇게 해서 완성된 pseudo label이 student model에 입력된다.
밑에 그림도 마찬가지. T은 turquoise라는 단어를 이해하지 못했다. Gold Data에 없었기 때문.
하지만 carribean sea는 알고 있었고, carribean sea turquoise를 같이 localize하면거 student 모델에게 turquoise에 대한 insight를 제공한다.
Prompt Tuning

왼쪽 case는 text없이 possible class만 주어졌을 경우
오른쪽 case는 image-text가 주어진 경우.
실험적으로 봤을때 논문에서는 오른쪽 flat and round라는 부연설명이 붙은 prompt가 예측 성능이 더 높았다고 한다.