Deep Pose는 2014년에 발표된 논문으로, Pose Estimation 분야에 최초로 DNN을 적용한 모델이다.
그 후로 많은 모델들이 등장했기 때문에, 최신 모델들에 비해 예측 성능은 좀 떨어지지만 여러 면에서 유의미한 논문이다.
우선 Deep Pose의 장점과 단점을 각각 살펴보면,
장점
- CNN을 사용해서 이미지의 전체적인 맥락을 예측에 사용했음. 당시에는 획기적. Deep Neural Network를 적용하는건 처음이었다.
단점
- 관절과 관절 간의 상관관계를 고려하지 않습니다. 관절이 겹쳐서 식별이 어렵거나,아예 가려진 경우 등등 한계점이 있는 data에서는 관절을 완벽하게 예측하기 어렵다.
- 계산이 비효율적이다. Cascase Model이어서 각기 다른 CNN 모델들을(구조는 다르고 weight를 각자 학습) 논문에서는 7개나(?) 사용했다.
- input을 정규화해서 학습하는데 그 정규화된 input의 size,scale이 정해져 있기 때문에 상황에 따라 정확도가 떨어질 수 있다.
Model
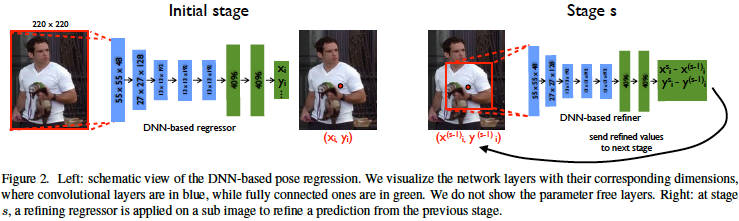
DeepPose는 Cascade Model을 사용한다.
여기서 사용하는 Cascade model이란 여러개의 CNN을 순차적으로 사용하는것이다.
Initial Stage 와 그에따른 Sequential Stage(1~S)로 구성이 되어있다.
Initial Stage
- 이미지 전체 or Person detector로 검출한 사람을 대상으로 관절을 에측한다.
- 총 k개의 관절에 대해서 예측 값을 내며 이는 총 2k 차원의 Vector(x ,y)좌표에 해당한다. 이를 식으로 나타내면 아래와 같다.
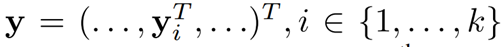
| x | 이미지 데이터 |
| y | pose vector |
| k | 관절 수 |
| $y_i$ | i번째 관절 x,y좌표 |

이때 좌표들을 이미지 내의 절대좌표로 처리하지 않고, Normalization을 한다.
Bounding Box라는 것을 만들어 $b_c$ 박스중앙, $b_w$박스 넓이, $b_h$ 박스 높이를 활용해 $y_i$를 정규화한다.

BB를 기준으로 정규화한 좌표들은 후에 본 이미지로 맵핑할때 정규화 과정을 거꾸로 적용한다.

x : 입력 이미지
φ : CNN 모델을 통과시키는 함수
θ : 학습되는 파라미터
여기까지가 Initial Stage과정이다. 이제 Initial Stage에서 CNN을 통해 구한 k개의 좌표들 하나하나를 대상으로 또 CNN을 진행한다.
Stage S
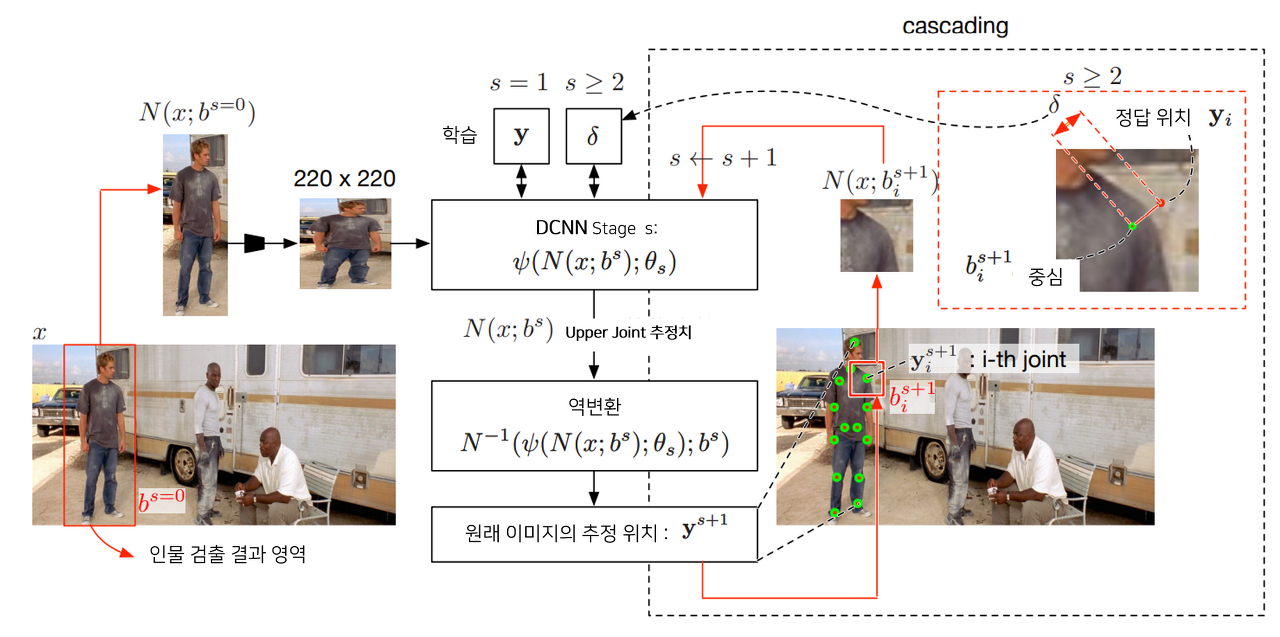
그 다음 $s>=2$인 Stage들에서는 각 Joint에 bounding box를 처서 관절부분 이미지를 고해상도로 추출한다. 새로운 bb로 추출한 이미지를 다시 s단계만큼 반복한다.
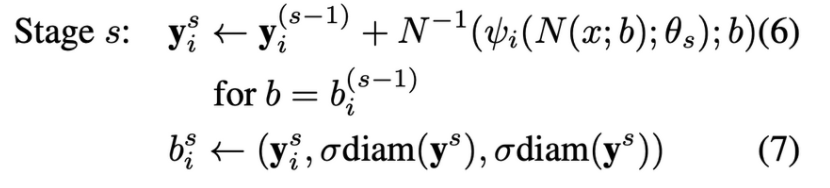
diam($y_s$) : 이전에 예측한 좌표들에서 왼쪽 어깨와 오른쪽 엉덩이 좌표 간의 거리
σ : diam(y)를 적당히 키워주는 파라미터입니다.
Loss
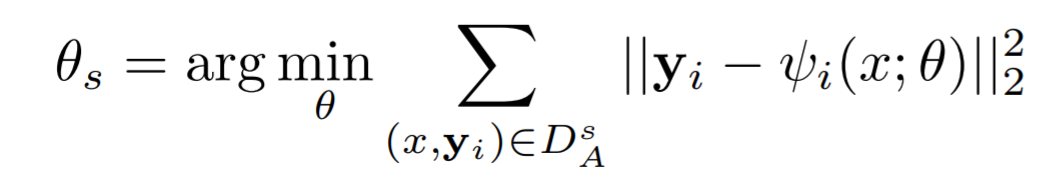
loss는 간단하게 GT와 예측 값의 L2 distance를 구한다.
'Deep Learning > Pose Estimation' 카테고리의 다른 글
| [Pose Estimation] HR Net - Paper review (0) | 2021.07.05 |
|---|