HR Net은 Human Pose estimation 분야에서 SOTA(State of the art)모델을 달성한 모델로 2019년에 발표되었다.
https://arxiv.org/pdf/1902.09212v1.pdf
Single person을 estimate하는 모델이고, 기존의 high-to-low resolution 네트워크에 비해 HR Net은 네트워크 내내 high resolution을 유지할 수 있다는 장점이 있다.
1. Introduction
HR Net은 Single person의 pose를 estimate하는 모델이다.
하나의 객체 안에서 pose를 추출해내는 방법은, multi-person pose estimation 이나 video pose estimation등의 문제에서 베이스가 된다.
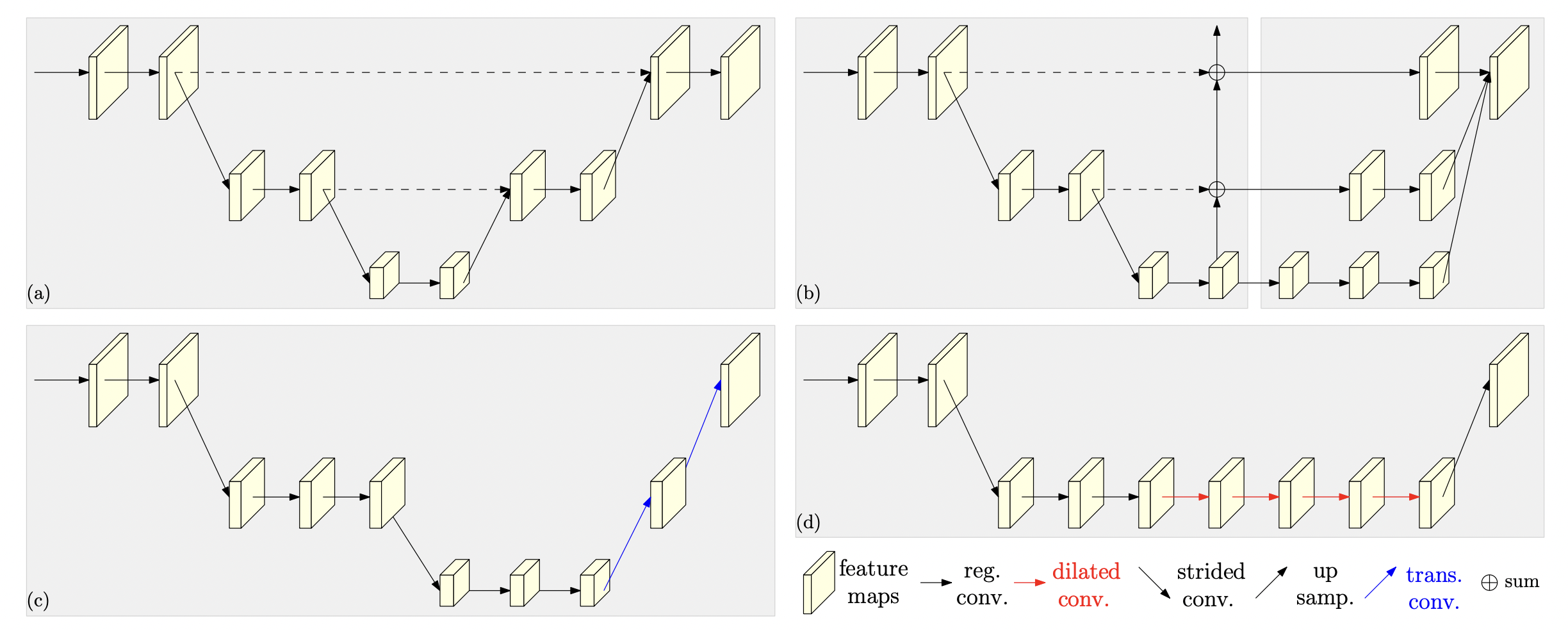
기존에는 high-to-low 또는 low-to-high process를 사용하거나 이를 섞어서도 사용했다.
그 과정에서 downsampling, upsampling 이 반복적으로 사용되었다.
(a)의 Hourglass model같은 경우 high to low to high를 사용한다. 그리고 skip connection으로 각 scale별 downsampling 하기 전 feature map을 upsampling한 feature map 에 더해준다. 이렇게 resolution에 다양한 변화를 주며 각각 다른 scale의 feature에서 유의미한 정보를 추출하는 방법은 흔하게 사용되어 왔다.
HR Net도 마찬가지이다. 근본적으로는 scale에 변화를 주면서 다양한 resolution에서 정보를 추출한다. 그럼에도 불구하고 다른 모델들보다 성능이 좋은 이유와 차별성에는 2가지가 있다.
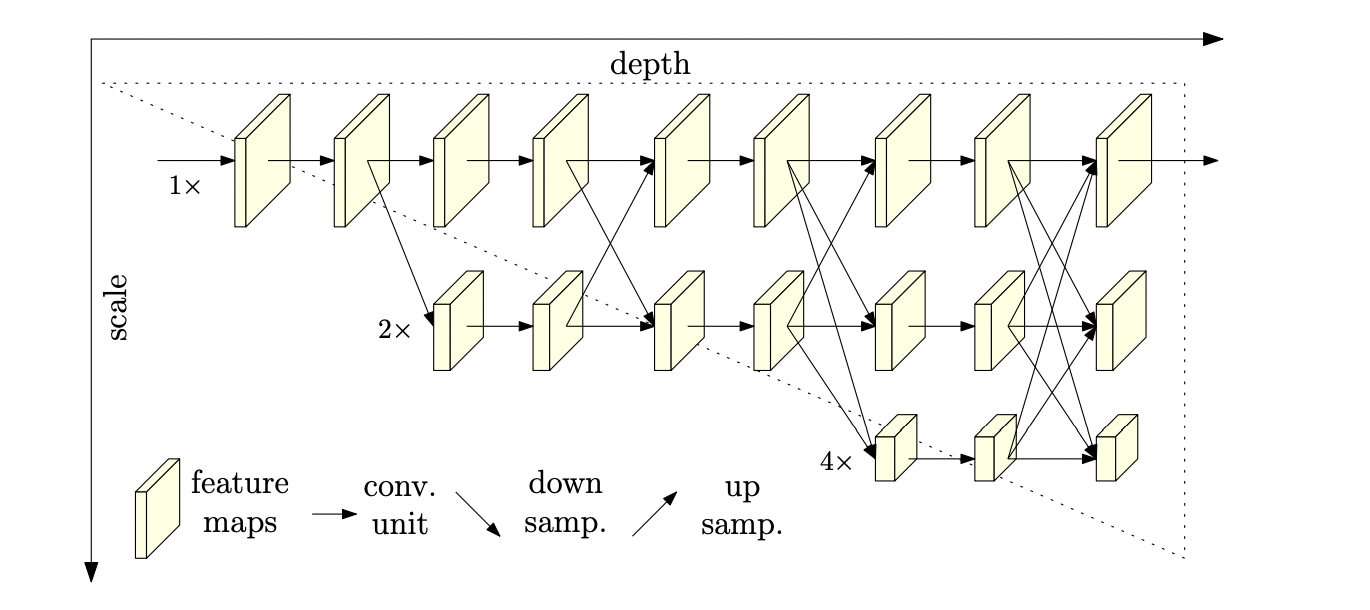
1. High-to-low resolution을 Serially(X) Parallel(O)하게 적용한다. 이게 무슨 의미인지는 아래에 나와있다.
기존 : Input받은 strand가 downsample 됨.
HR : Input 받은 strand의 해상도는 쭉 유지가 되고 거기서 평행하게 downsample되는 strand가 분리된다.
이렇게 되면 최종적으로 predicted된 heatmap에 한번도 downsample/upsample되지 않은 input해상도 feature map이 영향을 주기 때문에 훨씬 정확하다.
2. Repeats multi-scale fusions
기존 : 존재하는 대부분의 기법은 low-level and high-level representation을 더한다.
HR : parallel한 sub-network간에 계속 정보를 주고 받는다. (그림을 보면 쉽게 알 수 있음)
같은 depth와 유사한 level의 low-resolution representation을 보조로 사용한다. predicted heatmap도 더 정확한 결과를 보인다.
결과적으로 HRNet의 경우 다양한 해상도의 subNet을 병렬적으로 유지함과 동시에 exchange unit을 통해서 전체적인 맥락과 국소적인 정보를 지속해서 교환하는 특성이 있다.
2. Approach
Sequential multi-resolution subnetworks (기존)

$N_{sr}$ : Subnetwork in the sth stage and r is the resolution index
Parallel multi-resolution subnetworks (HR)

- $N_{sr}$에서 앞자리는 stage, r은 downsample된 단계를 의미한다. \
- $N_{sr}$은 첫번째 subnetwork($N_{11}$)의 해상도의 $\frac{1}{2^{r-1}}$
- high-resolution subnetwork을 처음 stage로 시작한다.
- high-to-low resolution subnetworks을 하나씩 추가한다.
Repeated multi-scale fusion
다양한 scale을 반복적으로 fusion하는 괴정에서 Exchage Unit이란게 사용된다.
Exchange Unit이란 병렬 subnetowrk간에 정보를 전달해주는 역할을 하는 유닛이다.

서로 다른 resulution의 정보를 합칠때는 적절하게 upsampling / downsampling이 필요하다.
아래 그림은 stage 3를 여러 exchange block으로 나눈 그래프이다. $C_{sr}^b$는 r번째 resultion, sth stage, bth block의 convolution unit을 의미한다.

- $C_{sr}^b$에서 s,b를 무시하고 r만 남겨놓는다. (resolution에 따른 차이만 보겠다는 의미)
- Input response maps: {} (resolution 단계는 1~S)
- Output response maps: {} (resolutions and widths = input)
- $Y_k = \sum_{i=1}^{s}a(X_i,k)$ Each output is an aggregation of the input maps
- $Y_{s+1} = a(Y_s,s+1)$ → Last Exchange Unit
Heatmap Estimation
최종적으로 heatmap은 Last exchange unit $Y_{s+1}$으로부터 나온 high-resolution representations output 으로 regress한다.
Loss Function은 평균 제곱 오차 MSE를 사용한다. 여기에 사용되는 GT heatmap은 각 keypoint에 2D 가우시안 분포를 적용해서 구한다.
Network Instantiation
ResNet 사용, resolution이 반으로 줄어들때마다 channel은 2배로 증가시킴.
3. Experiments
- COCO dataset 사용
- Evaluation Metric : OKS
OKS = $\frac{\sum_{i}^{} exp(-d_{i}^2 / 2s^2k_{i}^2)\delta (v_i>0)}{\sum_{i}^{}\delta(v_i>0)}$

※ Higher HRnet
Higher HRNet의 논문에선 기존의 HRNet에 추가적인 모듈을 달아주는 방법으로 개선하고자 한다.
추가적인 모듈은 deconvolution 레이어와 Residual Unit으로 구성되며, 높은 해상도의 heatmap prediction을 만든다.
논문에서는 하나의 모듈만을 사용할 경우 좋은 성능을 보인다고 하였지만, 때에 따라 여러 모듈을 적층해 성능 향상이 가능함을 보인다.
Higher HRNet의 경우 여러 해상도의 출력값을 만들어 낸다. (HRNet에서는 input 사이즈의 heap map만을 출력)
따라서 학습을 진행할 때는 supervision을 여러 해상도에서 진행하고, 테스트 단계에서는 출력을 평균냄으로 heatmap 예측값을 얻는다.
이 과정을 통해 scale에 따른 문제를 해결했다고 한다.
[참고]
'Deep Learning > Pose Estimation' 카테고리의 다른 글
| [Pose Estimation] DeepPose : Human Pose Estimation via DNN - Paper Review (0) | 2021.07.05 |
|---|