You Only Look Once !
Yolo는 v1~v5까지 다섯개의 버전이 있다
YOLO v1 : 1stage detector 최초 등장
YOLO v2 : faster, stronger, better . 3가지 측면에서 향상
YOLO v3 : multi-scale feature maps 사용
YOLO v4 : 최신 딥러닝 기술 BOS사용
YOLO v5 : 크기별로 모델 구성 - small, medium, large, xlarge..
YOLO의 특징은
1. Region Proposal 단계가 없다
2. 전체 이미지에서 bbox와 bbox의 클래스를 에측하는 일이 동시에 진행이 된다. (맥락 이해↑, 전체를 보니까)
YOLO v1
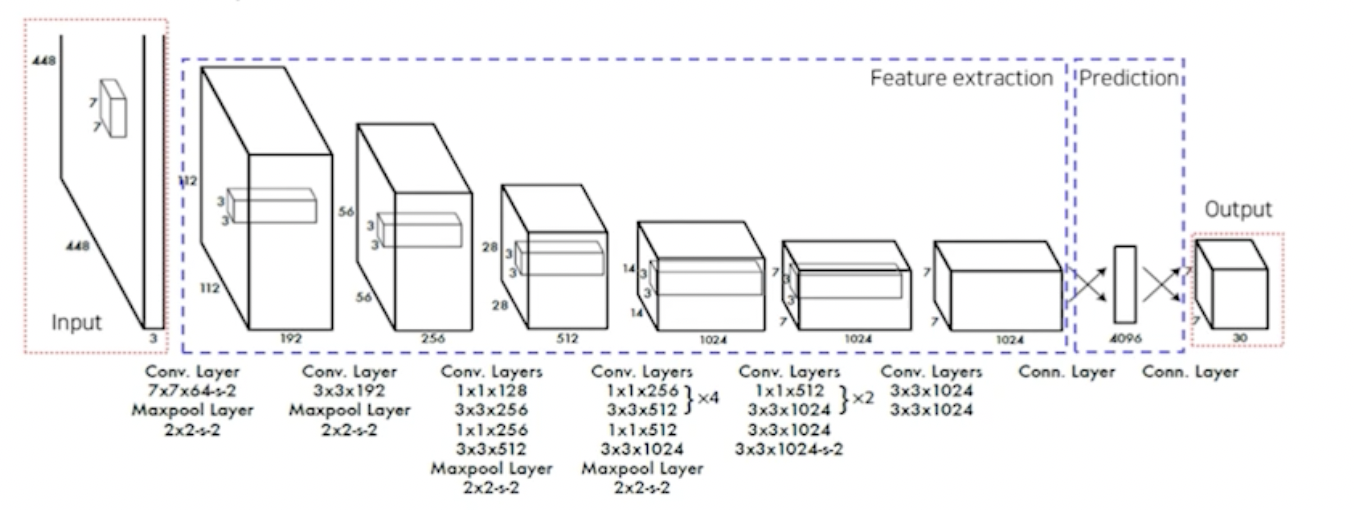
1. Pipeline
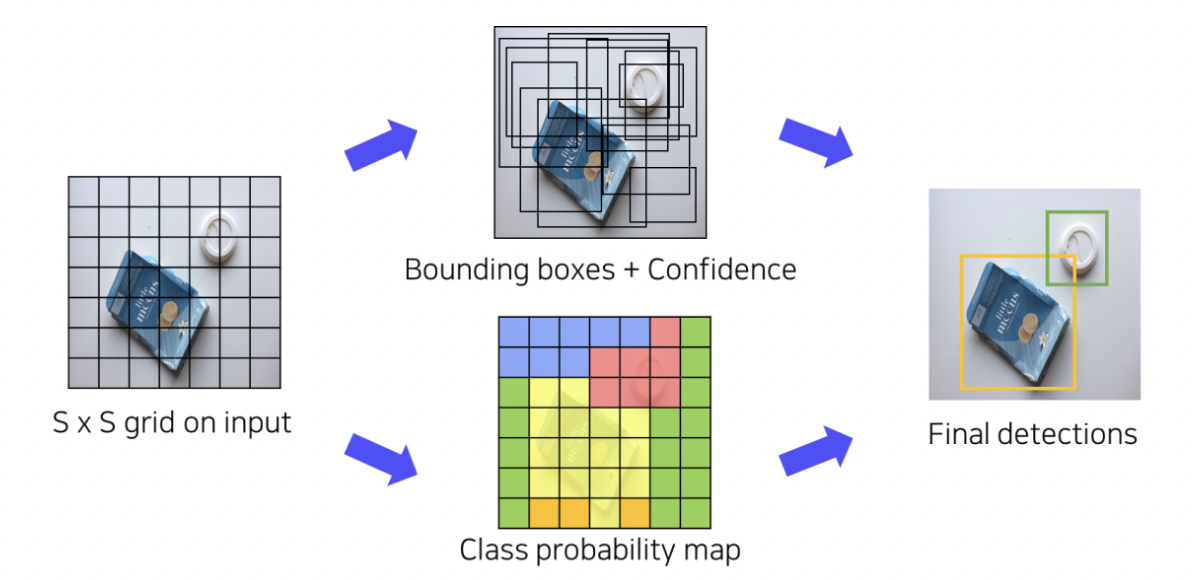
1단계 : 입력이미지를 SxS 그리드 영역으로 나누기 ( S = 7 )
2단계 : 각 그리드 영역마다 B개의 서로 다른 Bbox와 confidence score 계산 ( B = 7 )
3단계 : 각 그리드 영역마다 C개의 class에 대한 해당 클래스일 확률 계산 ( C = 20 )
최종 output은 7x7x30이다.
7x7은 그리드 사이즈. 그럼 나머지 30은??


- 그리드 셀마다 2개의 bbox 존재 -> 5x2 = 10!
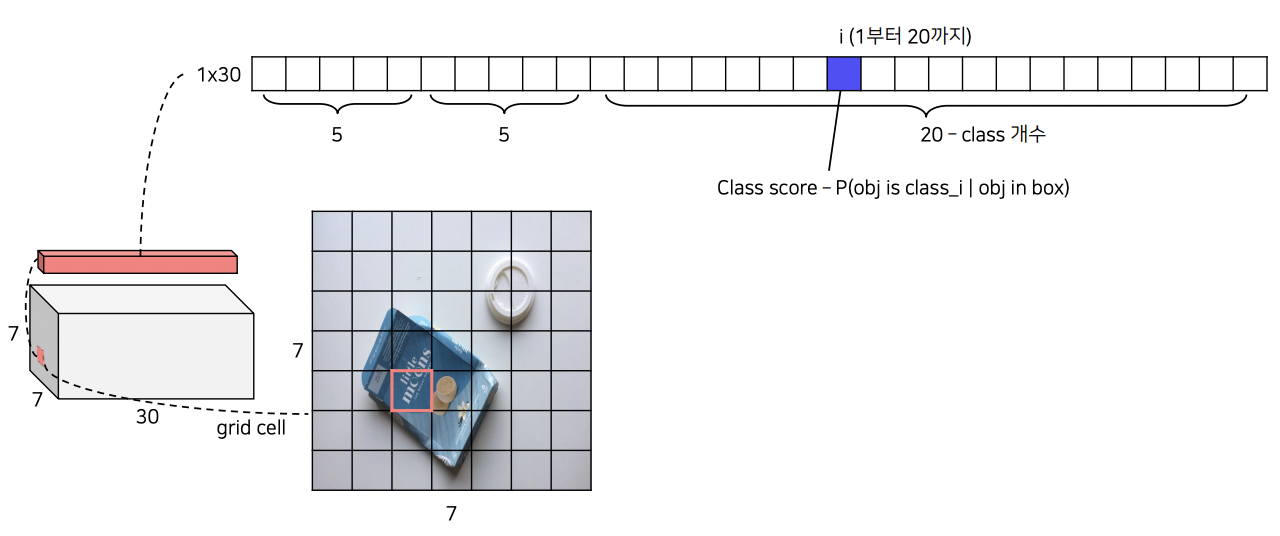
그 후, 각 bbox의 confidence( bbox가 객체를 포함하고 있을 확률 ) X 각 class score ( 해당 클래스일 확률)
을 계산해
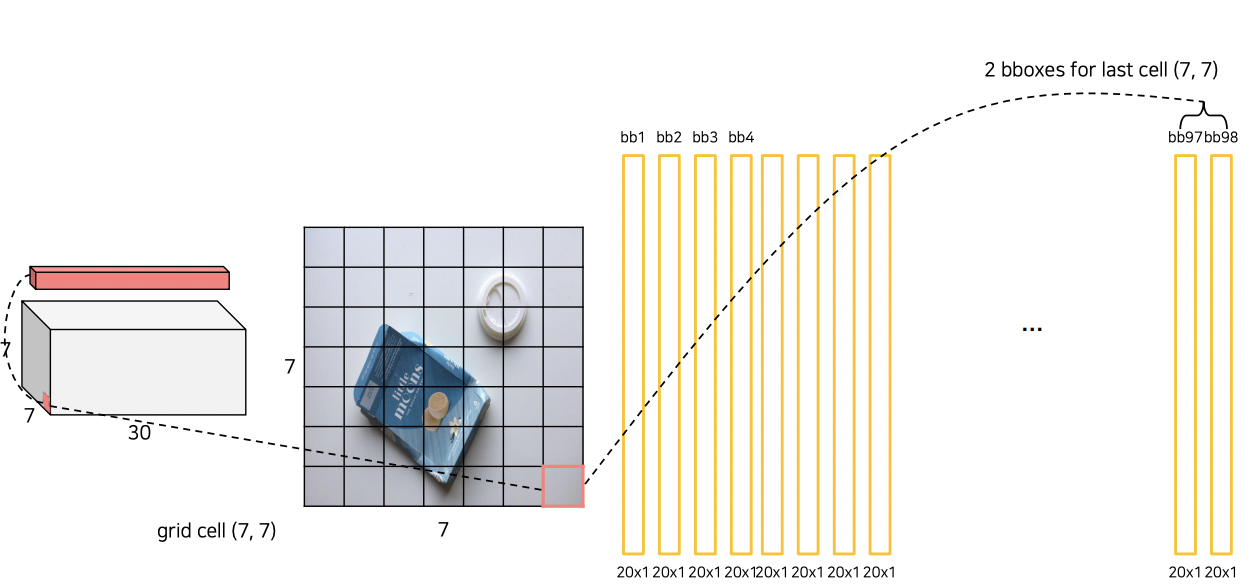
총 7x7x2(box 개수) x 20(Class) = > 20D vector 98개
2. Loss

Localization Loss, Confidence Loss, Classification Loss 총 3가지 Loss를 합쳐서 최종 Loss를 구한다.
- Localization : 각 object bbox의 x,y에 대한 loss와 w,h에 대한 loss를 더함.
- Confidence : Object가 있는 bbox대상으로 loss + Object없는 bbox대상으로 loss 더함
- Classification : Object 별로 class 정답과오차 loss
3. 장점
- Faster RCNN보다 6배 빠르다
- 기존 real time detector보다 6배 빠르다
- 이미지 전체를 봐서 맥락파악에 유리하다. -> 물체의 일반화된 모습을 학습해서 새로운 도메인, new dataset에도 굳건함
4. 단점
- 7x7 그리드로 나눌때, 그리드보다 작은 크기의 물체는 검출할 수 없다
- 신경망 마지막 feature만 사용한다. 정확도 bad
YOLO v2
Better! Faster! Stronger!
- batch normalization
- Anchor Box 도입 - v1에서는 각 그리드 셀마다 bounding box 좌표값 랜덤으로 초기화 후 학습
- Detection dataset, Classification dataset 같이 사용.!!!!

YOLO v3
Multi-scale Feature maps - 서로 다른 3개의 scale사용
Feature pyramid network사용 - high&low level 융합
'2021 네이버 부스트캠프 - Ai tech' 카테고리의 다른 글
| Week 8/9/10 - Object Detection - RetinaNet (0) | 2021.11.06 |
|---|---|
| Week 8/9/10 - Object Detection - SSD (0) | 2021.11.06 |
| Week 8/9/10 - Object Detection - 1-Stage-Detector (0) | 2021.11.05 |
| Week 8/9/10 - Object Detection - BiFPN , NASFPN, AugFPN (0) | 2021.11.05 |
| Week 8/9/10 - Object Detection - DetectoRS (0) | 2021.11.05 |