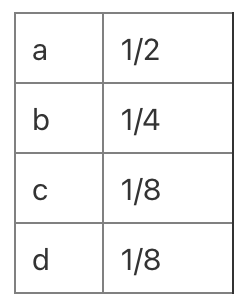
이번 글에서는 지난번의 정보이론 소개에 이어 딥러닝에서 많이 등장하는 Cross Entropy를 다루겠다. Cross-Entropy는 딥러닝에서 손실 함수로도 사용되고 KL, JSD, f-deivergence등에서도 많이 보이기 때문에 중요한 개념이다. 정보량과 Entropy의 개념이 확실히 이해되지 않는다면 이전글이나 다른 자료를 참고해서 공부한 후에 보는것을 추천한다!! Entropy Reminder 먼저 Entropy를 다시 떠올려 보자. $$ \sum_{x=1}^{N}-p(x) log p(x)$$ 분포 p에 대한 entropy다. (위 식에서는 밑의 값에 2가 들어왔지만 다른 숫자도 올 수 있다. 가령, $e$) $p(x) $ : x의 확률 $log_2 p_i$ : x의 정보량 여태까지 entro..