Recurrent Neural Network, 줄여서 RNN은 여태까지 배웠던 CNN 이나 FCN과는 조금 다른 특성을 지닌다.
이름에서 힌트를 얻을 수 있는데, 'Recurrent'는 되풀이하다, 순환하다와 같은 뜻을 지닌다. 왜 Recurrent인지 이유를 생각해보면서 읽으면 이해에 도움이 될거 같다.
"Vanilla" Neural Network
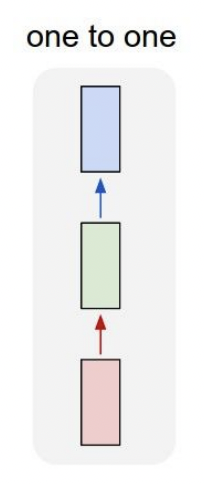
여태까지 배웠던 Neural Network들을 강의에서는 "Vanilla" Neural Network이라 했다.
Input에서부터 Output까지 feed-for
ward 하며 중간의 hidden-layer들을 거쳐 흘러간다.
이때, Input으로는 고정된 사이즈의 이미지나 벡터가 들어갔다.
Output으로는 classification 결과 값 같은게 나올 수 있다.
(그 외에도 다양한 유형의 output 존재, GAN같이 이미지를 output 할수있다.)
RNN은 이런 one-to-one network 보다 훨씬 더 자유도가 높다. 아래 그림과 같이 input과 output의 형태가 다양하게 구성될 수 있다.
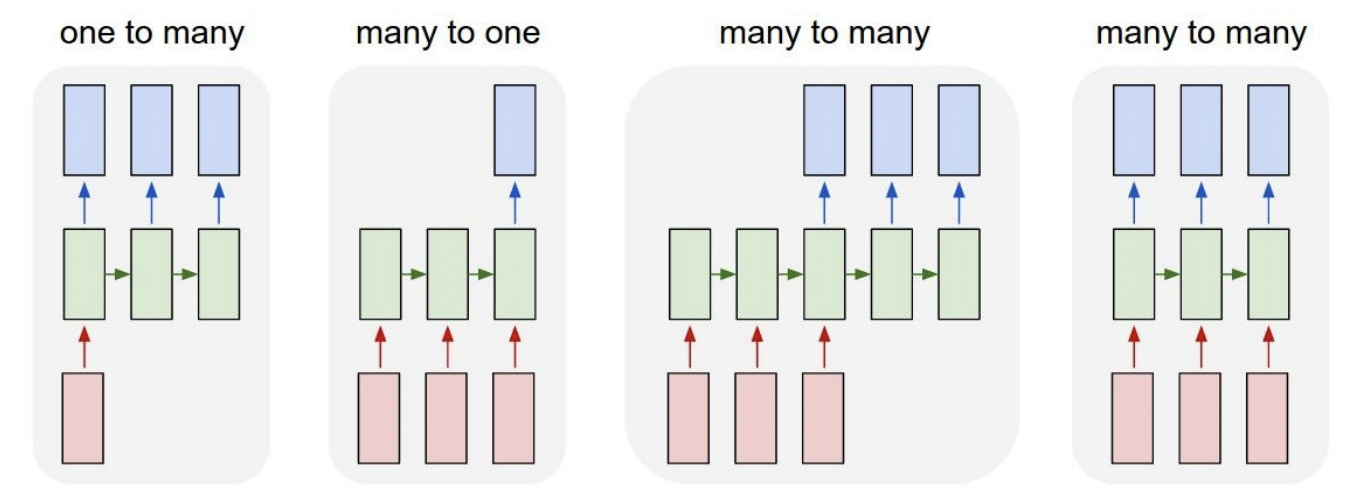
[다양한 형태의 Network 예시]
- one-to-many : Image Captioning(하나의 이미지 → 여러 단어, 출력의 길이기 가변적이다)
- many-to-one : Sentiment Classification(하나의 문장 → 감정분류, 입력의 길이가 가변적이다)
- many-to-one : Action Classification(비디오의 여러 프레임 → 동작분류, 입력의 길이가 가변적이다)
- many-to-many : Machine Translation(문장 → 문장, 입력문장과 출력문장의 길이가 가변적이다)
- many-to-many : Video Classification(비디오의 여러 프레임 → 프레임별 상황설명, 입력과 출력이 가변적이다)
위 예시들처럼 RNN이 다룰 수 있는 입력과 출력은 광범위하고, 정의하기 나름이기 때문에 flexibility가 크다.
RNN 구조
그럼 RNN은 어떤 구조로 이루어져 있을까?
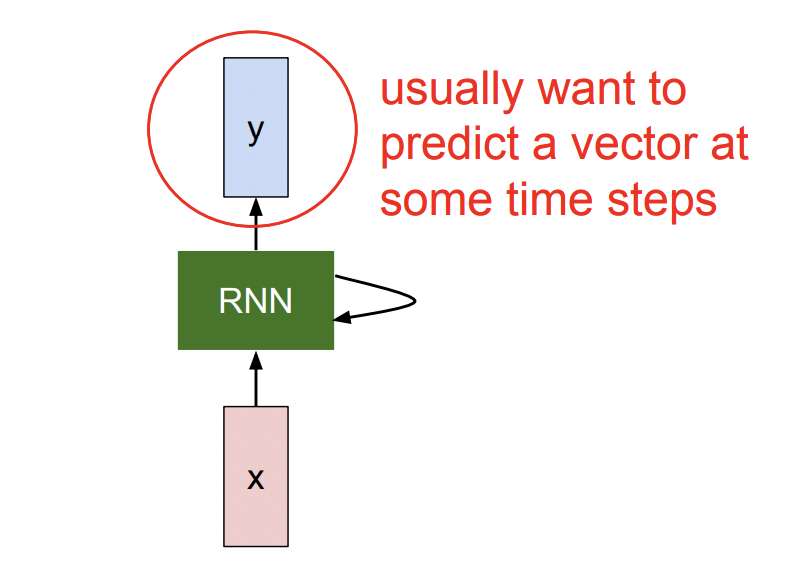
Input x가 RNN을 거쳐 Output y로 출력이 된다. 여기까지만 봐서는 CNN과 FCN과 크게 다른점을 찾을 수 없다.
한가지 차이점은 RNN에서 다시 RNN을 가리키는 화살표이다.
RNN은 Recurrent network로 Hidden Layer와 같이 Hidden State 라는것을 갖고 있다. 이 Hidden State는 X가 들어올때마다 기존 Hidden State에서 update되고, X읽어오기→ Hidden State 업뎃→ Y 추출의 흐름으로 처리된다.
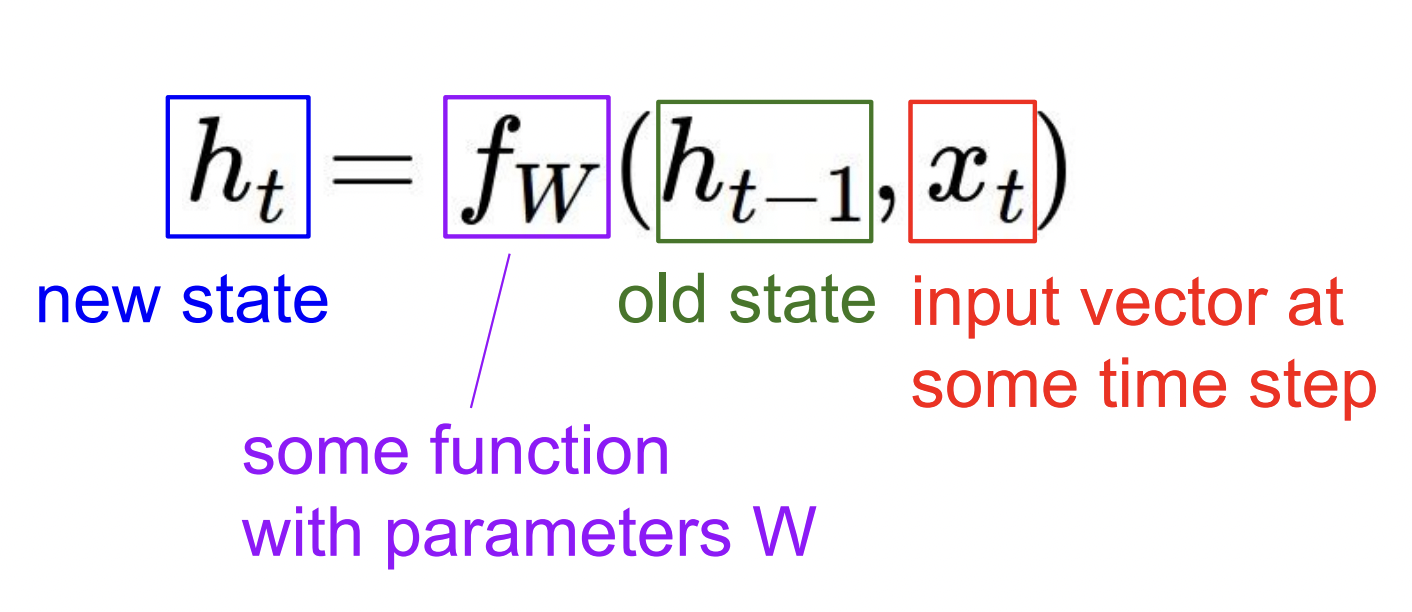
Hidden State 함수는 위와 같이 구성된다. t는 각 time step(시점)을 의미한다. $y_t$를 구할땐 $h_t$(현재 상태)를 이용해 FCN을 구성하기도 히고, 말고도 다양한 방법이 있다. function $f_W$는 항상 같은 함수를 의미한다.

"Vanilla" RNN은 Hidden State의 구조가 가장 단순한 RNN모델이다. 여기에 이것저것 더 첨가한 RNN에는 LSTM이 있고 뒷부분에 나온다.
- Hidden state를 구하는 활성화 함수로 tanh 사용
- 총 세개의 Weight parameter가 있다.
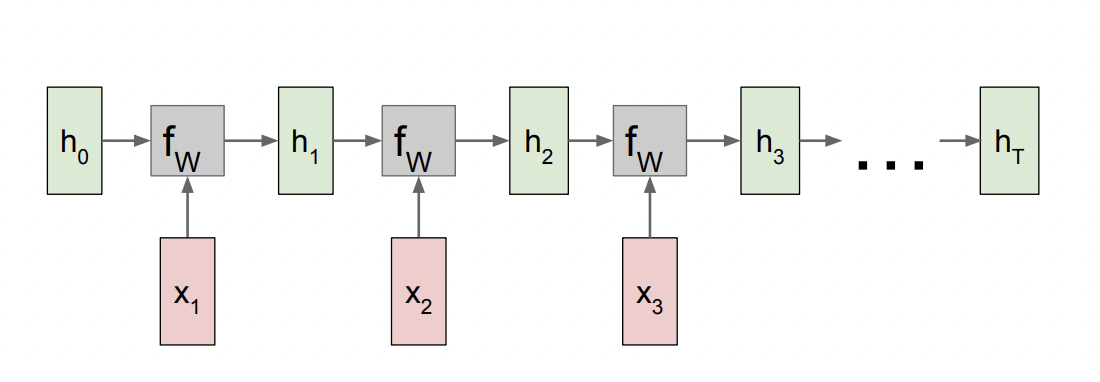
Vanilla RNN을 여러개 이은 모양이다. h0( initial state)에 x1을 넣어 다음 state h1을 생성한다.
h2도 마찬가지로 이전 state h1과 현재 input x2를 더해 만들어진다.

W matirx는 매 time step마다 fW에서 재사용 된다. 따라서 $f_W(h_{t-1},x_t)를 계산하는 과정에서 h와 x는 전에 사용된적 없는 unique한 값을 전달받지만, W는 계속 같은걸 사용한다. Back Prop에서 Gradient가 어떻게 계산되는지를 리마인드 해보면 같은 노드(여기서는 W)가 여러번 사용되면 dlos/sW는 결국 그 모든 gradient들을 합친 값이 된다.
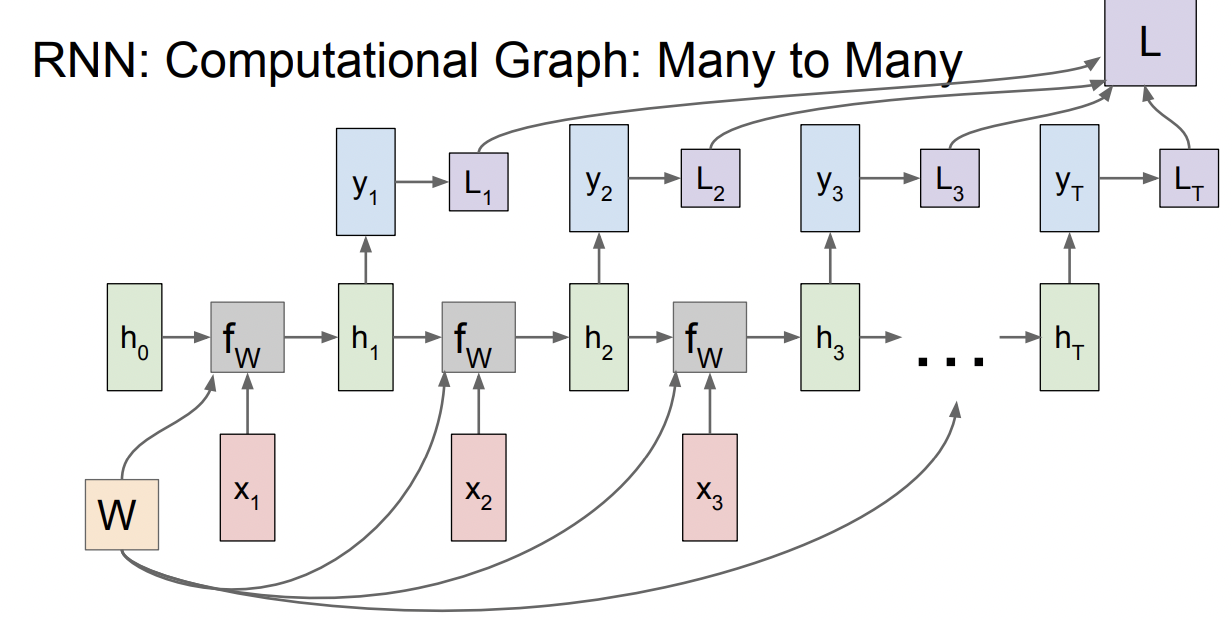
output y도 각 time step 별로 구해질 수 있고, Loss도 time step마다 Ground truth와 비교해 구해질 수 있다. 최종 loss는 individual loss의 총합이다.
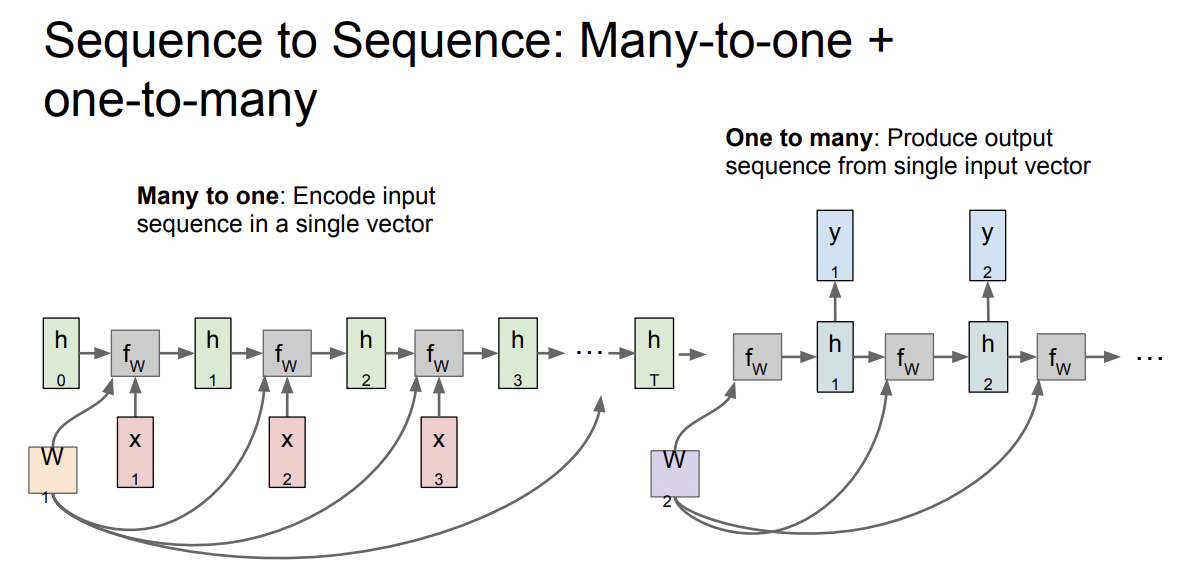
RNN으로 Encoder - Decoder구조를 만들어서 사용할수 있다. 왼쪽이 Encoder 파트, Many to one이다.
번역기의 예시를 들어 설명하면, 한 문장을 단어 단위로 x1, x2,...xt로 나눠서 input으로 쓰고 문장을 압축해 하나의 hidden state vector로 출력한다. Many vector 가 One vector로 변했다. 그리고 최종 hidden state vector은 문장에 대한 정보를 함축해서 갖고 있다.
Decoder에는 함축된 hidden state vector를 입력으로 받아 y1,y2,...yt(어떤 단어를 쓸지)를 출력해 다른 언어로 번역한다.
RNN은 따라서 언어 모델을 처리하기에 적합하다. 이전 정보와 새로운 정보를 함축적으로 지니고 있는 Hidden state의 특성이 유기적으로 연결되어 있는 언어의 특성에 잘 맞기 때문이다.
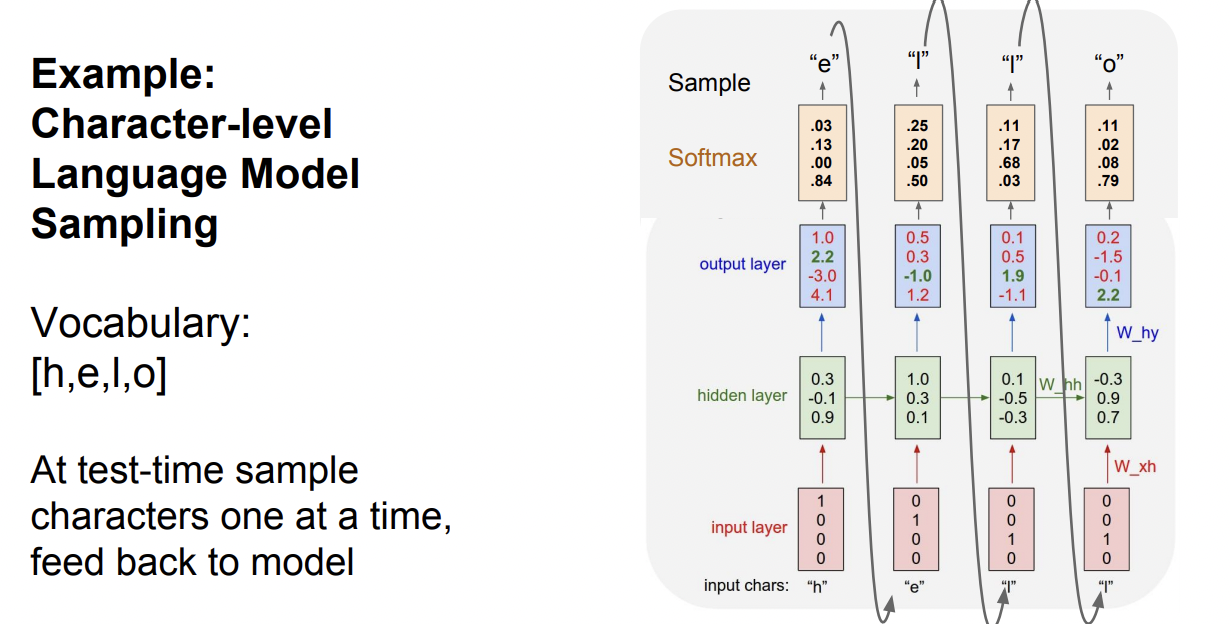
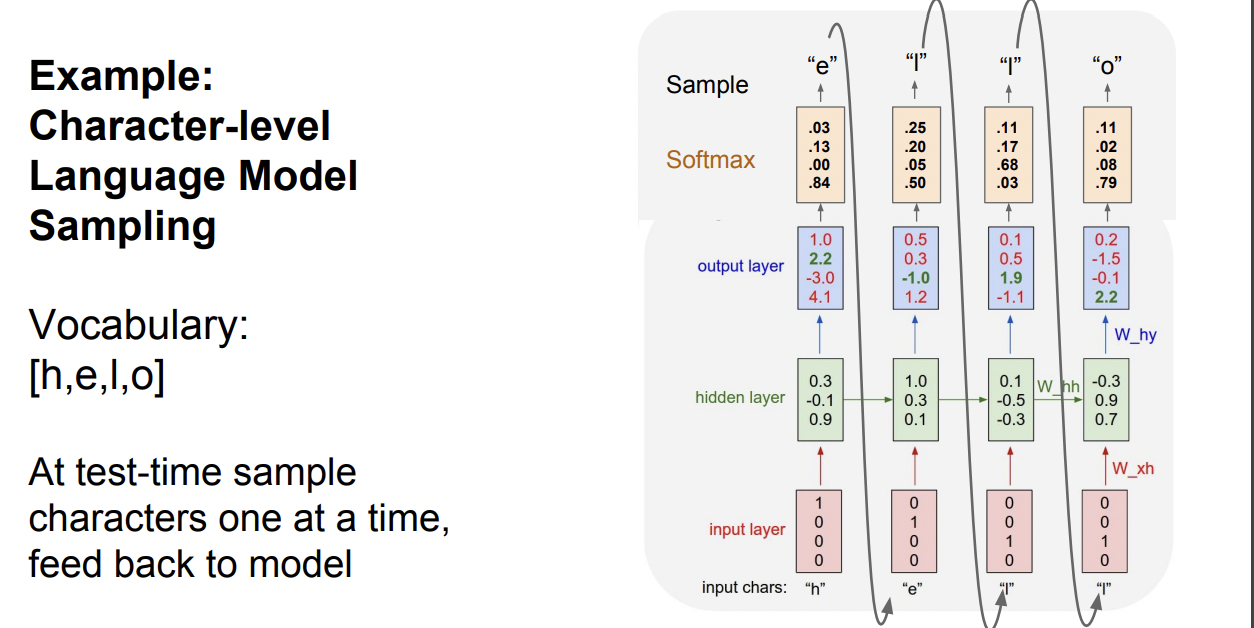
'hello'라는 단어를 예측하는 예시이다. hello 는 h,e,l,o로 이루어져 있기 때문이 이를 원핫벡터로 바꿔 input으로 준다.
Character vector를 input으로 받은 hidden layer는, 아래 식을 계산해 h와 t를 구한다. W는 계속 재사용된다.
$$h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)$$
$$ y_t = W_{hy}h_t$$
Back Propagation 문제점
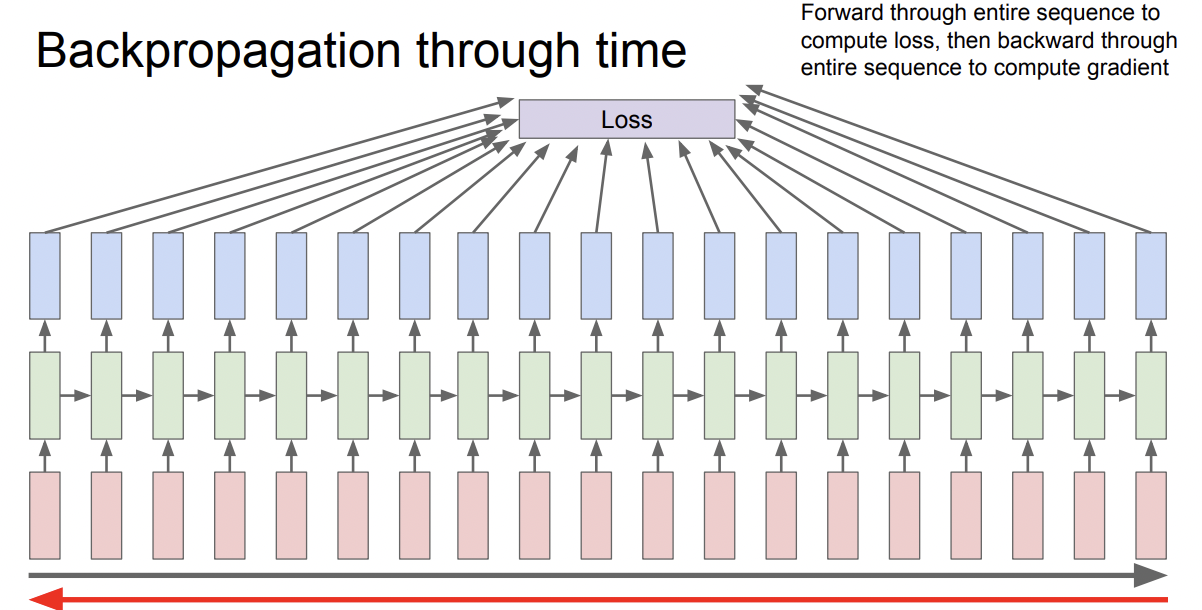
이런 sequential data를 처리하면 Back Prop에서 문제가 발생한다. forward / backward pass를 한번 할때마다 모든 step을 계산해야하는데 만약 input이 무지막지하게 길어서 연산양이 많다면? gradient가 수렴할 가능성도 매우 낮아질 뿐더러 시간과 메모리측면에서 낭비가 심하다.
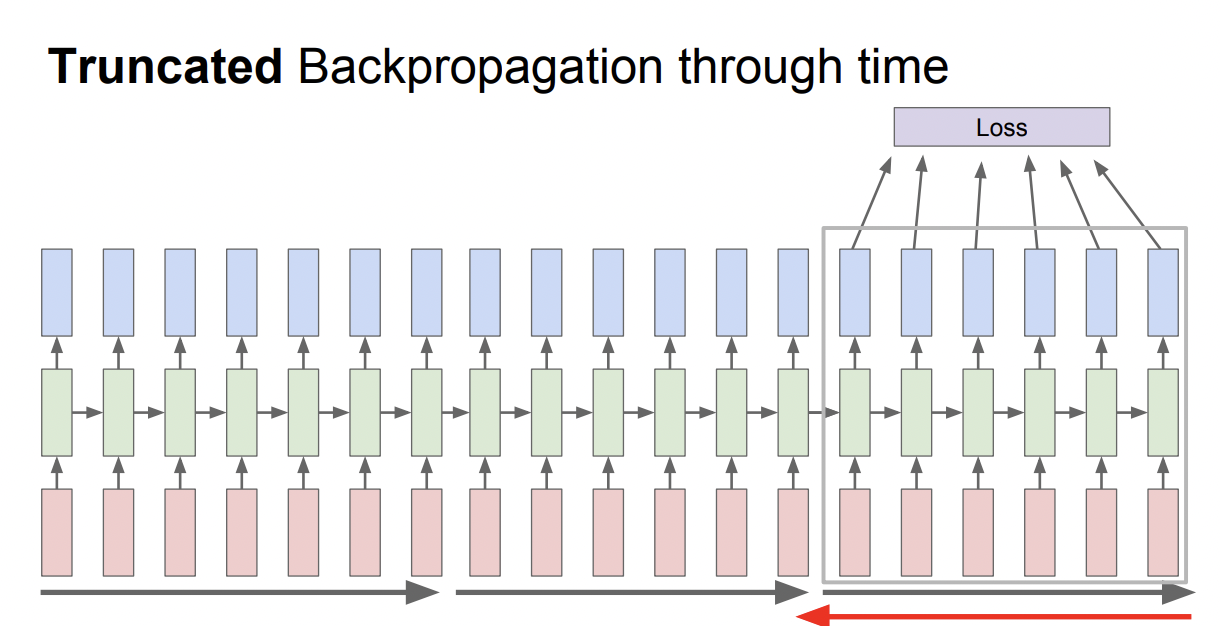
Truncated Backpropagation은 sequence를 구간으로 나눠서 feed-forward와 back-prop시에 해당 구간 내에서만 계산하는 방법이다.
https://gist.github.com/karpathy/d4dee566867f8291f086
Vanilla RNN Gradient Flow
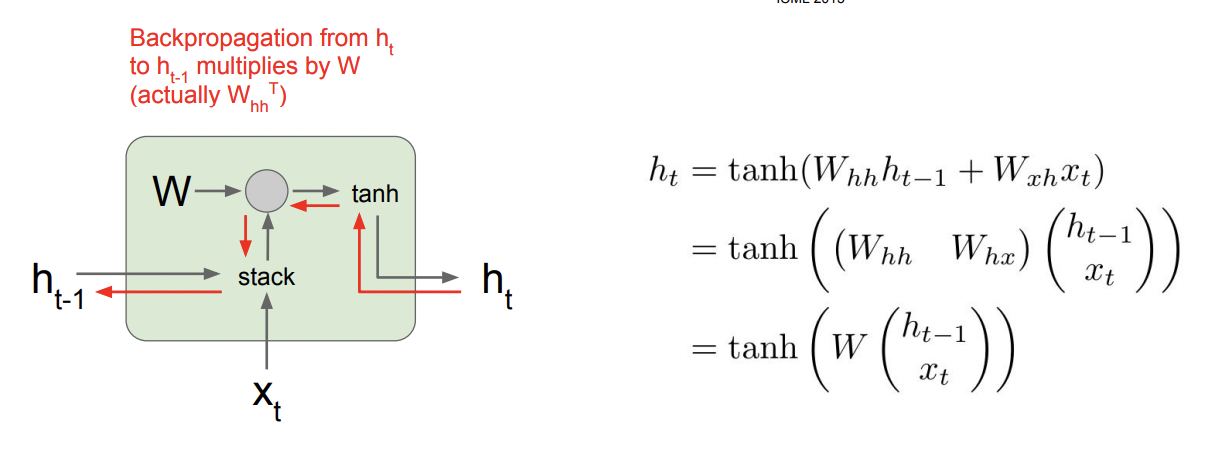
한 개의 hidden state를 구하는 과정을 들여다 보면 위와 같은 흐름으로 gradient들이 이동하는것을 알 수 있다. 초록색 네모를 하나의 cell이라고 하자. 하나의 cell에서 gradient를 구하는것은 별로 어렵지 않아보인다. 하지만 h1 ~ ht까지 여러 cell을 거쳐온 gradient를 구할때는 문제가 발생한다.
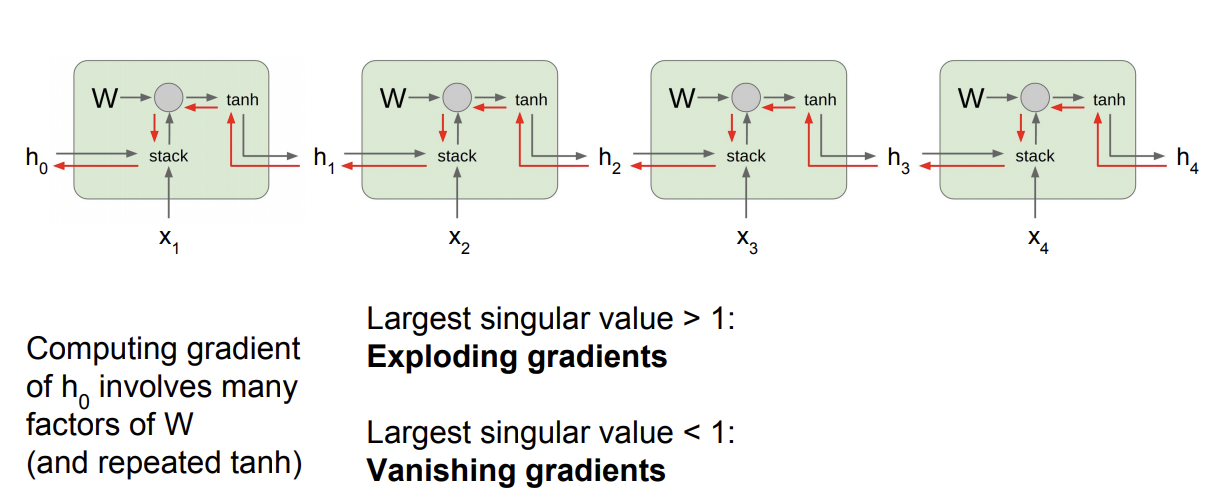
Loss에 대한 h0의 gradient를 구하면 gradient W가 반복적으로 곱해진다. 동일한 수가 반복적으로 곱해질때 문제가 생기기 쉽다. 그 수가 1이 아닌이상 1보다 작으면 매우 작은 수로 점점 수렴하면서 Vanishing gradient problem이 발생하고, 반대로 1보다 크면, 너무 커져 Exploding Gradient problem이 발생할 것이다.
Exploding Gradient problem의 해결방법은 Gradient Clipping이다.
Gradient Clipping : 만약 L2 norm값이 threshold 보다 너무 크면 작아지는 쪽으로 scaling하는 기법
하지만 Vanishing Gradient Problem일때는 RNN을 구조적으로 바꿔줘야 한다. → LSTM의 필요성
LSTM
LSTM은 Long Short Term Memory의 약자로 RNN이 좀 더 원활한 Gradient Flow를 갖도록 설계한 Recurrent Network이다.
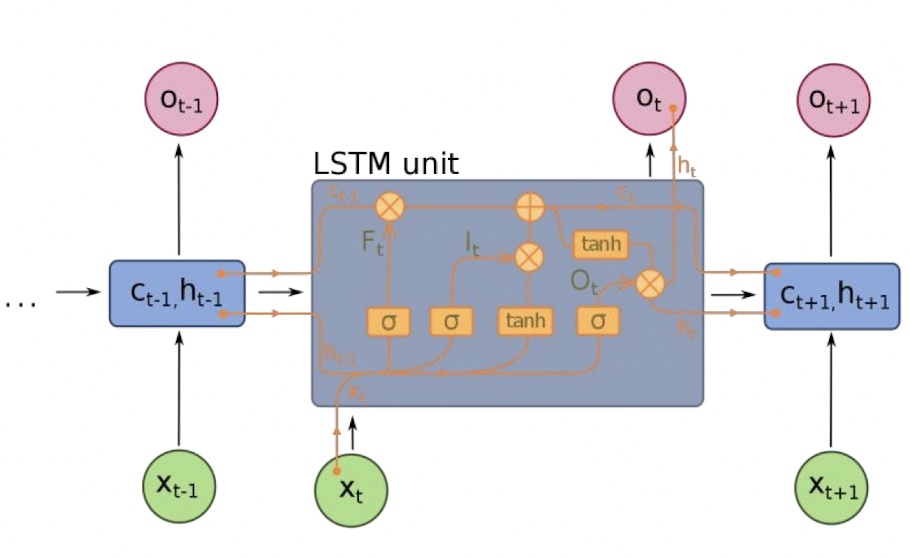
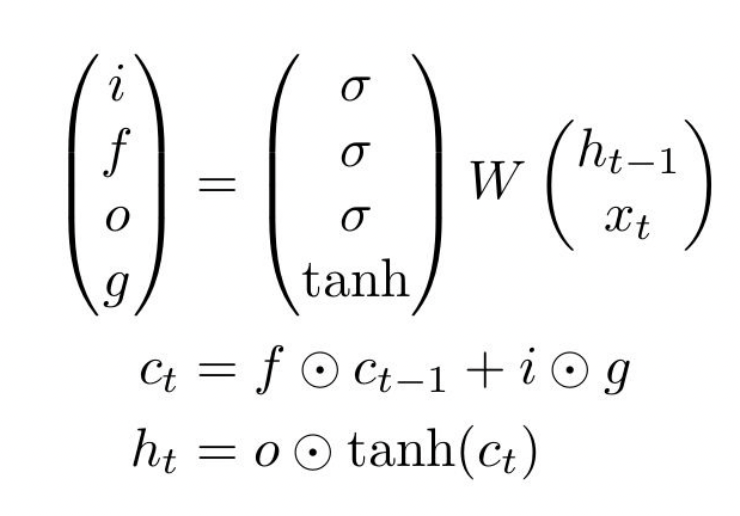
- f: Forget gate - cell의 내용 지울지말지
- i: Input gate - cell에 input 내용 쓸지말지
- g: Gate gate - 얼만큼 cell에 쓸지(?)
- o: Output gate - cell 내용을 output에 쓸지말지
LSTM을 다이어그램으로 나타낼대 개인별로 차이가 많기 때문에 무엇이 정답이라는건 아니다. (나도 처음 배웠을때 Gate gate는 배우지 않았었다.)

LSTM에서 back prop의 과정은 vanilla RNN의 단점을 많이 보완했다
- cell $c_t$를 back prop할때 cell과 forget gate가 matrix 곱이 아니라 element-wise로 곱해지기 때문에 역전파가 훨씬 더 간결해진다.
- 기존의 RNN에서는 계속해서 dW를 곱했기 때문에 동일한 값이 곱해서 explode or vanish하는 문제점이 발생했다. forget gate는 시그모이드를 통과하기 때문에 0~1사이의 스칼라값이다.
'cs231n > 내용 정리' 카테고리의 다른 글
| cs231n - 13강 - Generative Models (0) | 2021.07.18 |
|---|---|
| cs231n - 12강 - Visualizing and Understanding (0) | 2021.07.09 |
| cs231n - 11강 - Detection and Segmentation (1) | 2021.07.07 |
| cs231n - 7강 - Training Neural Neworks II (0) | 2021.06.23 |
| cs231n - 6강 - Training Neural Networks I (0) | 2021.06.23 |