*본 글은 cs231n 13강의 내용을 정리 요악한 글입니다.
오늘은 비지도 학습의 대표격인 생성모델에 대해 알아보겠습니다.
Supervised Learning vs. Unsupervised Learning
Supervised 일명 지도학습은, 학습데이터의 label, 정답이 주어진 학습법입니다.
아래 그림과 같이 고양이 사진에 'cat'이라는 label이 주어지고, 또 여러 물체가 있을때 어떤 물체가 각각 어떤 클래스에 속하는지 label이 주어지기도 합니다.


이처럼 주어진 데이터와 그 label을 학습하며 새로운 data와 그에 따른 label을 맵핑하는 함수를 찾는데 지도학습이라고 할 수 있습니다.
반대로 Unsupervised Learning, 비지도 학습은 정답 레이블이 주어지지 않고 데이터를 잘 포착해 결과물을 도출하는 학습방법입니다.
머신러닝의 K-means clustering 같은것을 예시로 들 수 있습니다.
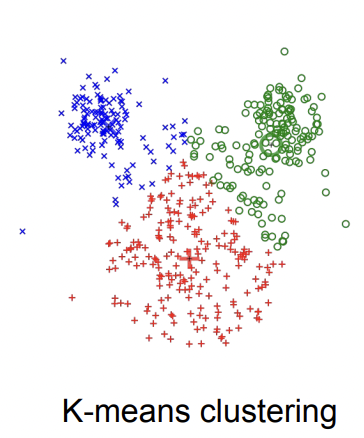
label이 없기 때문에, data의 hidden structure를 찾아내는게 목표입니다.
종종 책이나 강의에서 지도학습은 이끌어주는 선생님이 있고,
비지도 학습은 혼자 배워나가는 독학과도 같은 느낌이다. 라고 소개가 되어 있는데요
지도학습이 좀 더 쉽기 때문에(?) 비지도 학습은 그에비해 아직 미개척 학문인 느낌이 큽니다.
또한 data에 label을 일일히 붙이는 작업이 필요없고, 그저 데이터만 있으면 바로 사용 가능하기 때문에 data가 cheap하다는 장점이 있습니다.
Generative Models

레퍼런스가 될 training data가 주어졌을때 그와 비슷한 분포를 가지는 new data를 생성하는게 생성모델의 역할입니다.
generative model이 전부 새로운 data를 생성하는 역할을 가지지만, 굵직굵직한 특성에 따라 아래와 같이 분리될 수 있습니다.
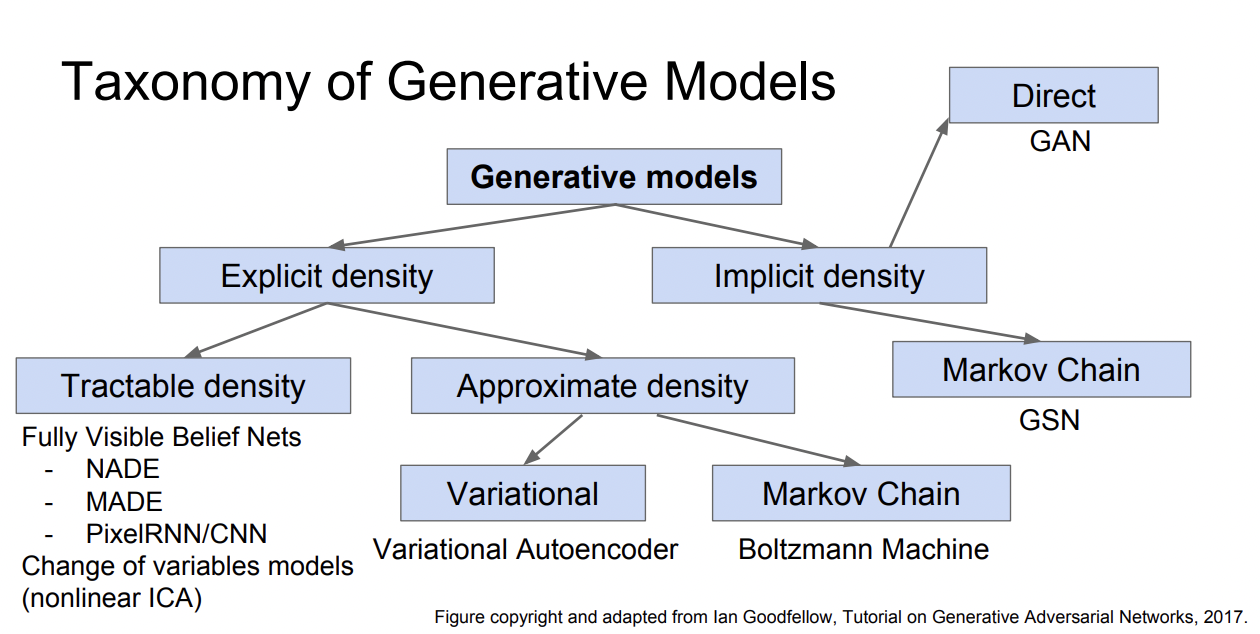
먼저, $p_{data}(x)$(실제 데이터 분포)에 근사하고자 하는 $p_{model}(x)$을 어떻게 정의하느냐에 따라 아래와 같은 큰 갈래로 나뉩니다.
Explicit density: $p_{model}(x)$이 어떤 분포를 띄는지를 정의하고 찾는데 초점을 둡니다.
Explicit density 모델은 training data의 likelihood를 높이는 방향으로 학습을 합니다. $x_1 ~ x_i$까지가 각 pixel이 등장할 확률이라면, 해당 pixel들로 구성된 이미지가 나타날 확률은 각 pixel들의 확률곱입니다. 따라서 아래와 같은 식으로 나타낼 수 있습니다. Loss도 계산할 수 있어서 학습 정도를 알 수 있습니다.
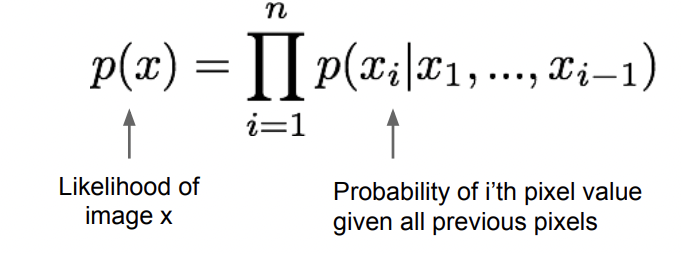
위에 장점만 보면 loss도 계산할 수 있는 explicit model이 훨씬 유리한 방법같아보일 수 있지만, 현재는 생성모델 중 GAN(implicit)이 제일 잘나가고 있습니다. 그 이유는 바로 모델을 정의하는게 한계가 있기 때문입니다. 데이터가 더 복잡해질수록 분포를 식으로 표현해서 계산하기 어렵기 때문에 implicit model쪽을 많이 택합니다.
Implicit density: $p_{model}(x)$이 어떤 분포를 띄는지 정의하는데는 관심이 없고, 단지 sample을 생성할 수 있는 수준을 원합니다. $p_{model}(x)$을 sampler로 사용.
지금은 무슨 차이인지 와닿지 않을 수 있습니다. 뒤에 나올 GAN의 내용을 보면 이해가 되겠습니다.
Pixel RNN - tractable density
Pixel RNN은 왼쪽 위 코너의 시작점으로 부터 상하좌우로 뻗어나가면서 이미지를 pixel by pixel로 생성하는 방법입니다.

이때 새로 만들어지는 픽셀은 인접한 픽셀들의 영향을 받아서 새로 생성됩니다. 이전 결과에 영향을 받는 구조에는 RNN이 적합하기 때문에, 이전 픽셀들에 대한 dependency 는 LSTM같은 RNN등으로 표현이됩니다.
- : 매우 느리다. feed-forward process같이 레이어를 몇번 거치면 뿅하고 나타나는게 아니라. 작업을 모든 픽셀에 대해 순차적,반복적으로 해야 된다.
Pixel CNN
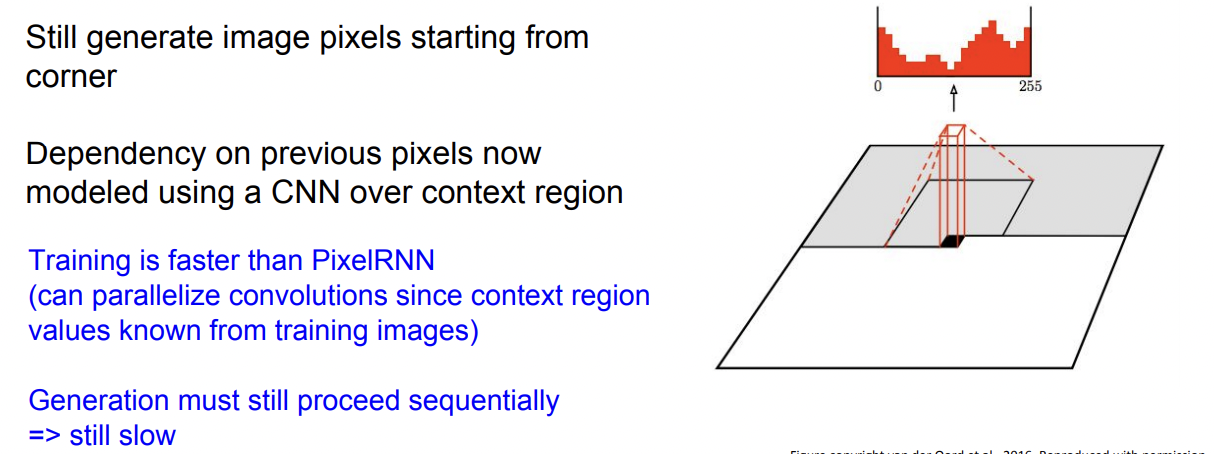
Pixel RNN의 에서 RNN을 CNN으로 대체한 방법이 Pixel CNN입니다.
Pixel RNN처럼 이미지의 한쪽 끝에서 시작하지만, 이미지 생성에 영향을 주는 인접한 좌표들에 한꺼번에 CNN을 하는 방식으로, Pixel RNN보다 빠르다는 장점이 있습니다.
위에서 본 방법은 ecplixit-tractable density function이었습니다.
지금부터 볼 VAE는 intractable density function입니다. (복잡해서 계산을 할 수 없다)
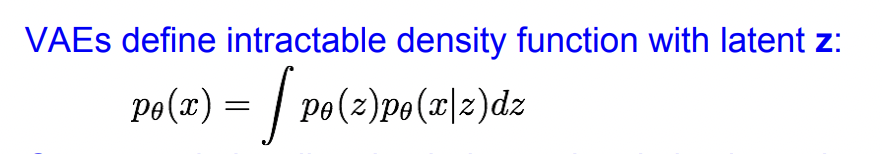
계산을 해서 직접 optimixe할 수 없기 때문에 function의 하한선을 찾아서 그 하한선을 maximize하는 방법으로 최적화를 대신합니다.
VAE의 background가 되는 AE를 먼저 살펴보겠습니다.
Auto Encoder
: Unsupervised approch to learn lower dimensional feature representtion from unlabeled data
: 레이블이 없는 데이터에서 feature representation을 뽑는 비지도 학습법
z: feature vector
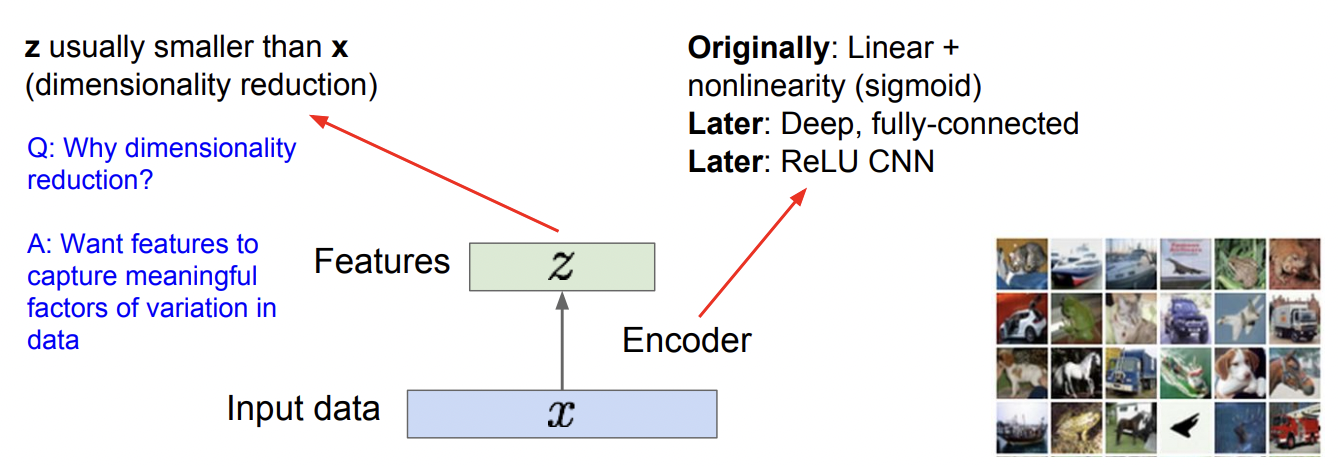
1. input data x 에서 feature vector z를 추출한다, downsample : Encoder
- x에서 의미있는 요소를 추출한게 z이기 때문에 대체적으로 z의 dimension이 x보다 작다.
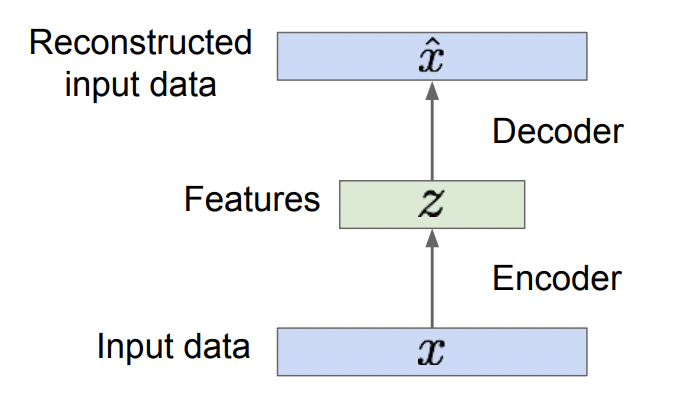
2. feature z에서 Recondtructed input data $\hat{x}$를 다시 만들어낸다, upsample : Decoder
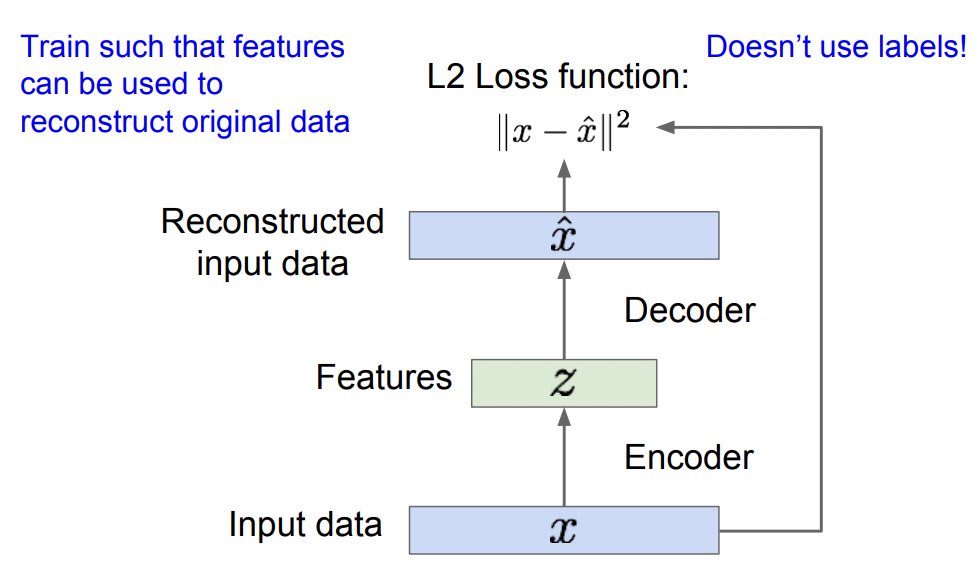
Auto-Encoder는 1번으로 z를 생성하고, 2번으로 $\hat{x}$를 생성해서 최종적으로
$x$와 $\hat{x}$차이를 최대한 줄이도록 feature z를 학습합니다.
no labels! $x$와 $\hat{x}$만 필요!!
Decoder는 사실상 주요기능을 하지 않습니다. z를 학습하는데 있어서 input x와 비교할 기준이 필요하기때문에, 그 기준이 되는 $\hat{x}$을 생성하는데 사용되는 도구일뿐. 따라서 학습후 그냥 버려지게 됩니다.
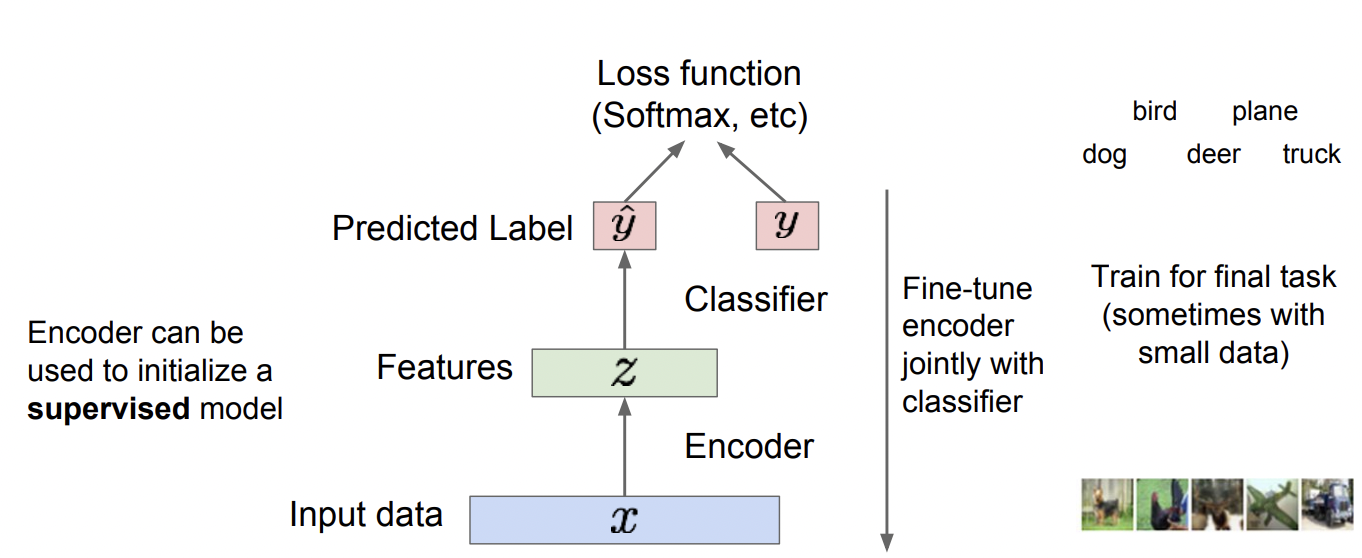
Decoder를 제거한 모델은 이제 feature만 남았습니다.
이 feature는 적절한 학습을 통해 input data x 의 중요힌 feature를 추출해 낼 수 있게 되었죠.
사실상 이 feature를 data의 특성을 잘 반영하게끔 추출해내는게 Auto Encoder의 목적입니다. Decoder는 도구였을 뿐이죠.
이제 이 feature는 supervised model의 input으로 들어가, classification 하는데 사용합니다. (Generative model이 아님!)
기존 classification과 비교했을때, 왜 이렇게 복잡한 거치는지에 대한 이유는 아래와 같습니다.
data가 넉넉하지 않을때, overfit/underfit되는걸 최대한 줄이기 위해 이런 방법을 사용합니다.
VAE
Auto-Encoder가 잘 추출한 feature를 사용해 이미지 클래스를 분류했다면, VAE는 이 feature로 새로운 이미지를 생성할 수는 없을까?하는 의문에서 출발합니다.
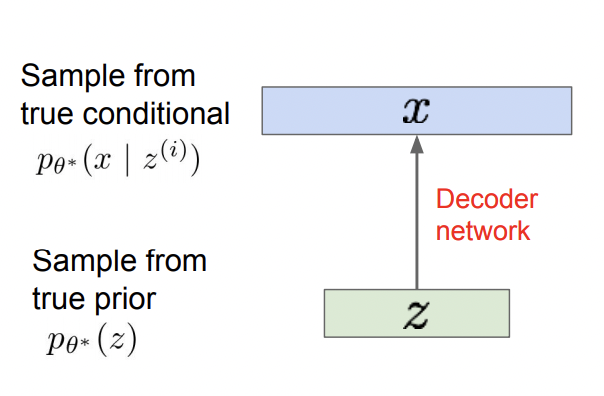
여기 vector z가 있습니다. 그리고 x는 이 생성모델에 latent vector z와 parameter $\theta $를 집어넣은 결과입니다.
- $z$: latent vector. Gaussian 분포같은 랜덤 노이즈가 들어가기도 함. ( Approximation )
- $p\theta*(z)$: parameter가 $\theta$일때, latent vector z를 sampling 할 수 있는 확률밀도함수
- $p\theta(x|z)$: parameter가 $\theta$이면서, z가 주어졌을 때 x를 생성해내는 확률밀도함수
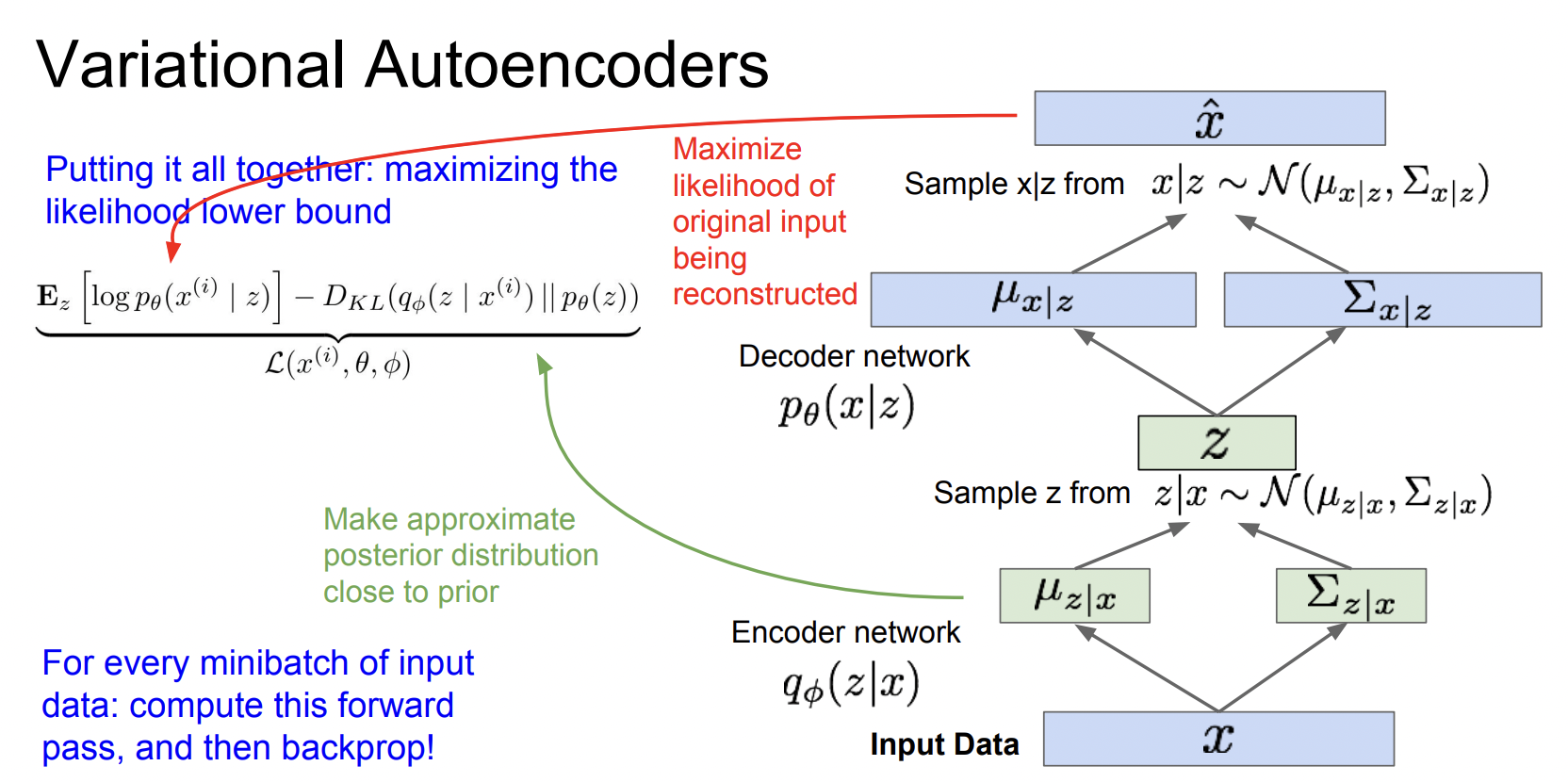
여기서 $\theta$를 실제 분포와 가깝게 찾는것이 목표입니다. 따라서 p(z)에서 p(x|z)를 만드는 Decoder network를 복잡한 구조도 핸들링 가능한 neural network로 구성을 하고, 아래와 같은
$p\theta(x)$ - paremeter가 $\theta$일때 x가 나올 likelihood를 최대화 시키는 방향으로 학습을 합니다.
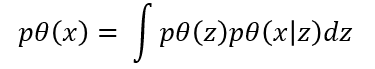
하지만 모든 z에 대해 p(x|z)의 적분을 취해줄 수 없다는 문제점이 있습니다. 이게 바로 intractable한 문제입니다. 계산이 불가능하다는 뜻입니다. 그래서 차용한 방식이 VAE입니다.

위에서는 decoder network만 있었다면 여기서는 encoder netowrk q를 추가합니다.
여기서 $q\phi(z|x)$는 $p\theta(z|x)$를 근사하는 encoder network입니다.
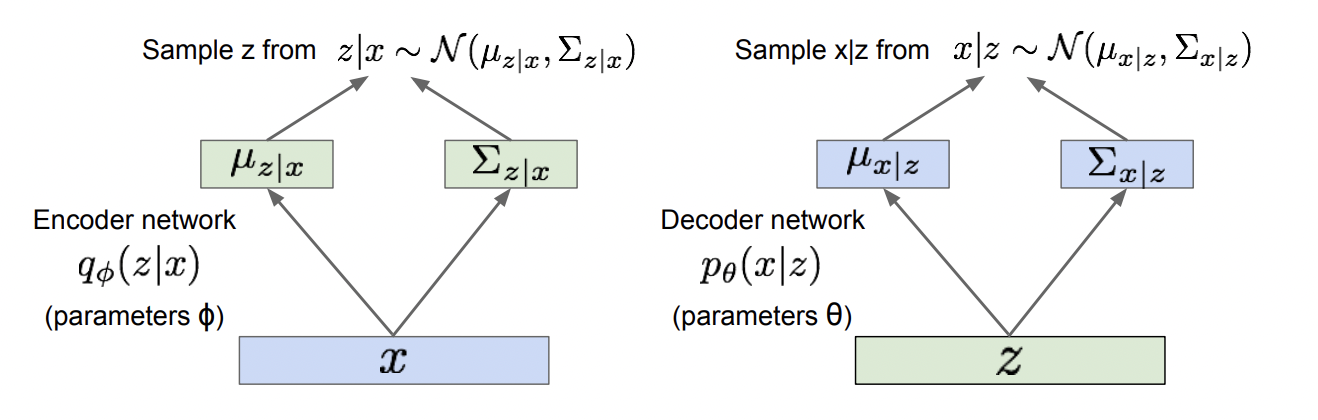
Decoder Encoder구조로 구성된 VAE네트워크의 구조입니다.
왼쪽은 Encoder, 오른쪽은 Decoder 네트워크입니다.
Encoder
- Encoder $q\phi(z|x)$ : x를 input으로 받아서 mean,covariance추출 후, z space상에서 분포를 생성.
- z는 gaussian 분포를 따른다고 가정.(예시일뿐, 다른 분포도 가능)
Decoder
- gaussian 분포로부터 z를 sampling.
- sampling한 z를 가지고 decoder $p\theta(z|x)$는 x space 상의 확률분포를 생성하고, x를 이 분포로부터 sampling
이러한 Encoder-Decoder x-> z ->x 구조를 가지기 때문에 Auto-Encoder라고 할 수 있고, 결과적으로 유의미한 feature vector z를 얻을 수 있습니다.
GAN (implicit density)
Generative Adversarial networks : 모델을 직접 optimize 할 수 없다. optimize는 포기하고 sampler의 기능을 극대화시키는 방법
GAN은 생성모델 중에서도 가장 성능이 좋다고 알려져 있고 아직까지 연구가 활발하게 진행되고 있는 분야입니다.
자세한 내용은 GAN을 따로 정리한 포스트를 참고해주세요!
[GAN] Generative Adversarial Nets - Paper Review
[GAN] Generative Adversarial Nets - 증명
더 읽을거리 😀
[GAN] DCGAN - 논문 리뷰, Paper Review, 설명 (1)
'cs231n > 내용 정리' 카테고리의 다른 글
| cs231n - 12강 - Visualizing and Understanding (0) | 2021.07.09 |
|---|---|
| cs231n - 11강 - Detection and Segmentation (1) | 2021.07.07 |
| cs231n - 10강 - Recurrent Neural Networks (0) | 2021.07.02 |
| cs231n - 7강 - Training Neural Neworks II (0) | 2021.06.23 |
| cs231n - 6강 - Training Neural Networks I (0) | 2021.06.23 |