2013년 발표된 RCNN은 최초의 Object Detection 모델이자, 이후 발표된 여러 모델들의 기준이 되는 중요한 연구다.
2 Stage는 이전 글에서 말했듯이 객체가 있을법한 위치 선정 + 클래스 판별 의 스테이지로 이루어진다.
1. Extracting Region Proposal

Region Proposal 알고리즘
- Extracting Region Proposals : input image에서 ROI 추출. 객체가 있을거라고 예상되는 부분을 bbox침
- Sliding Window : 다양한 scale로 무수히 많은 영역을 검출한다. 이미지의 대부분은 배경이기 때문에 sliding window기법을 사용하면 당연히 객체가 포함될 가능성은 줄어든다. 비효율적

- Selective Search : 이미지의 색/질감/모양 등 이미지의 '특성'을 활용해 추출. 무수히 작은영역~ 점차 통합해서 덩어리를 선택

2. Pipeline

1. Input image에서 Selective Search를 사용해 약 2000개의 ROI 추출.
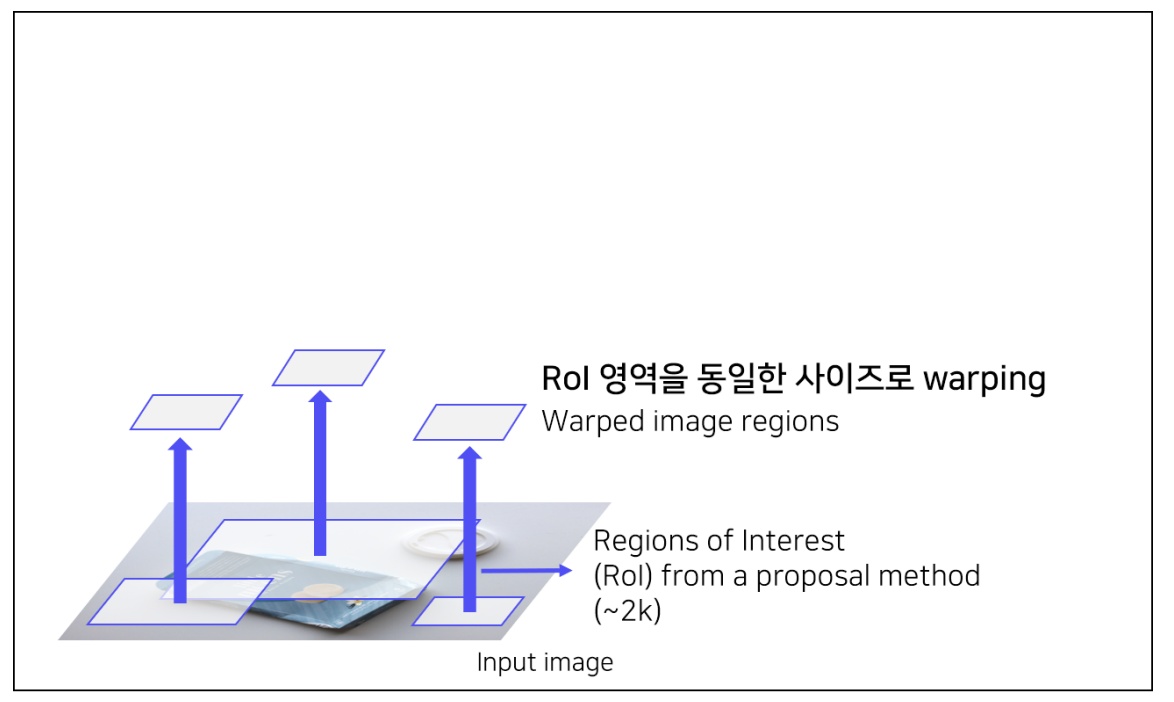
2. ROI를 전부 동일한 사이즈로 Resize
- 이후 class 판별 단계에서 CNN을 수행하는데, 마지막 FC layer가 고정된 size만을 받을 수 있기 때문에 ROI resize가 필수

3. n 개의 후보영역을 ROI를 CNN에 넣어서 유의미한 feature로 변환
- 각 region마다 4096D feature vector추출
-> 2000개의 ROI일때, 2000x4096
- Pretrained ALexNet 사용
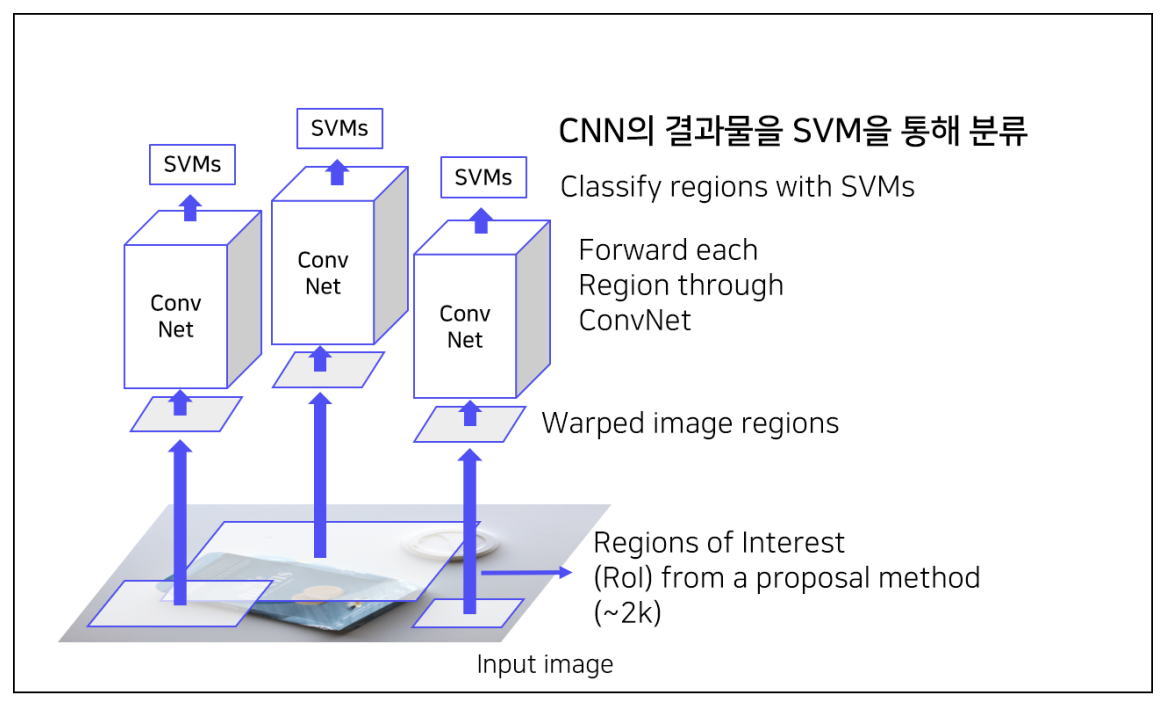
4. CNN을 통과한 feature SVM에 넣어서 분류 진행
- Output 1 : Class 개수 + Background 총 C+1개의 confidence Score

5. CNN을 통과한 feature에 Regression 통해 bbox 예측
- Output 2 : bbox좌표 (주로 중심점 x,y,W,H)
3. Training Trick - hard negative mining
Hard negative = False Positive. 객체라고 모델이 예측했지만 실제로는 배경이었던 case.
그말은 즉슨, 배경으로 판단하지 못한 까다로운 영역이라는 뜻이다.
따라서 이런 샘플들을 강제로 다음 배치의 negative sample로 mining하는 방법.
이걸 왜하냐?
1. 이미지에서 배경이 차지하는 비중 상당히 큼! 알뜰하게 사용해야함
2. 큰 비중의 배경샘플들을 quality있게 사용하고 싶어서
4. Shortcomings
- 2000개의 Regions이 각각 CNN을 통과한다 = CNN 2000번 = 연산량 폭발!!!!
- 이미지 resize, 강제 warping은 성능 하락의 가능성이 있다. (다영한 객체를 다 동일한 크기로 통일하기에는 무리가 있음)
- CNN, SVM classifier, bbox regressor 각각 따로 학습!!
- 여러 모델들이 따로 있기 때문에 End to End가 아님..
그래서 그걸 보완한 SPPNet!!!!은 다음글에
'2021 네이버 부스트캠프 - Ai tech' 카테고리의 다른 글
| Week 8/9/10 - Object Detection - Fast R-CNN (0) | 2021.10.15 |
|---|---|
| Week 8/9/10 - Object Detection - SPPNet (0) | 2021.10.15 |
| Week 8/9/10 - Object Detection - 2 Stage Detectors (0) | 2021.10.15 |
| Week 8/9/10 - Object Detection - Evaluation Metric (mAP, FPS, Flops) (0) | 2021.10.15 |
| Week 8/9/10 - What is Object Detection? (0) | 2021.10.15 |