FCN : Fully Convolutional Network
FCN은 Semnatic Segmentation task의 시초격인 모델이다.
초기 모델인 만큼 단점도 많지만 중요한 contribution 2개를 남겼다.
주요 Contribution
1. 1x1 Convolution
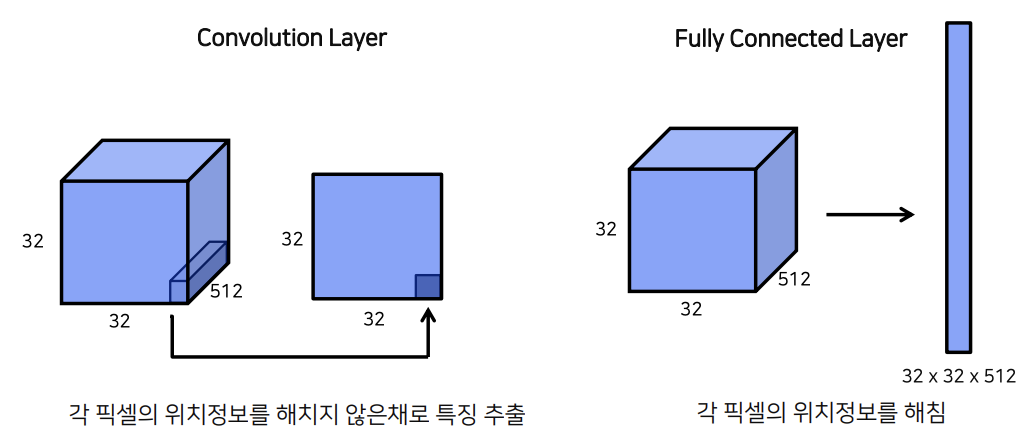
여기 32x32(HxW) x 512(C)의 shape를 갖는 feature map이 존재한다.
이 feature block을 fully connected layer에 집어 넣기 위해서는 Flatten해야 한다.
이 과정에서 32x32x512 = 524288의 1D vector가 생성되고 이 과정이 반복되면 될수록 pixel의 위치정보는 사라진다.
1x1 Conv를 사용하면 Resolution을 그대로 유지하면서 채널수만 원하는 수로 바꿀 수 있다.
= 각 픽셀의 위치가 보존된다.
첫번째 장점 : 위치보존
실제로 최종 결과를 확인해봐도,

Convolution Network에서는 각 score가 class 별로 추출되지만 Fully Connected 에서는 class 점수만 최종적으로 output 된다.
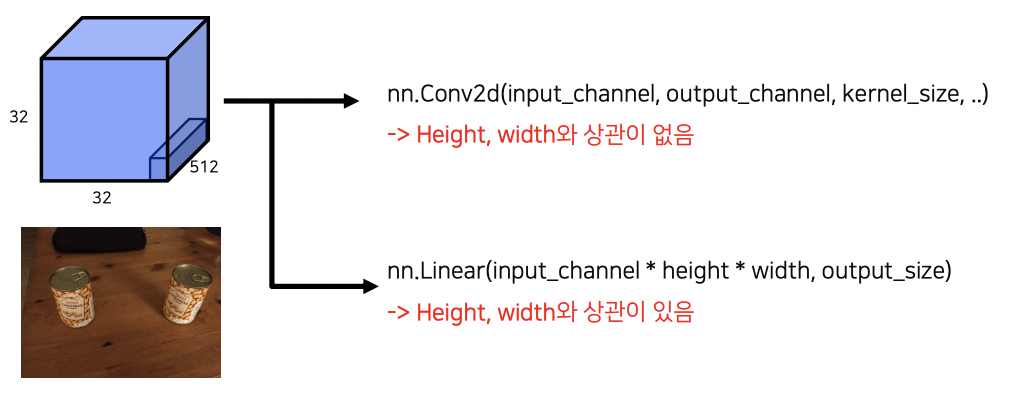
두번째 장점 : 입력이미지 크기와 무관한 결과
FCN의 1x1 Conv의 또다른 장점 중 하나는 입력 이미지의 resolution과는 상관이 없다는 점이다.
1x1 Conv는 채널사이즈를 원하는 데로 바꿀 수 있고 HxW가 어떻게 되는간에 모든 pixel에 동일한 연산을 취하기 때문에 입력이미지가 어떤 크기든 상관이 없다.
2. Transpose Convolution
Transpose Convolution은 간단하게 역 Convolution이라고 생각하면 된다.
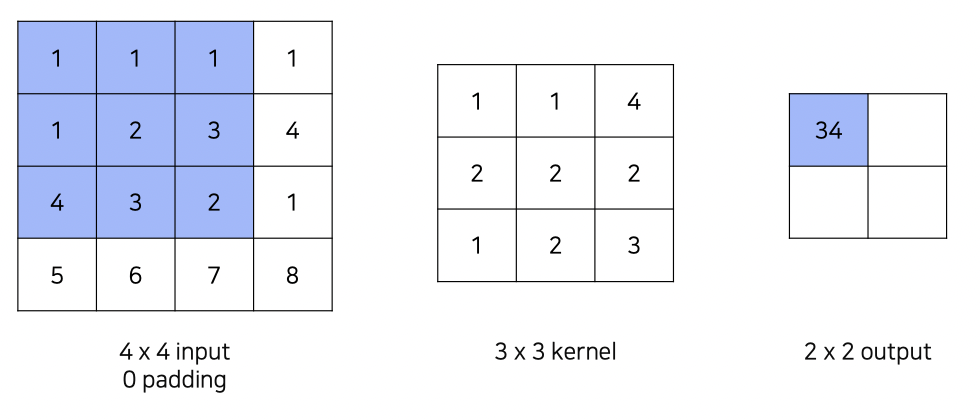
전통적인 convolution이 왼쪽과 같다면,
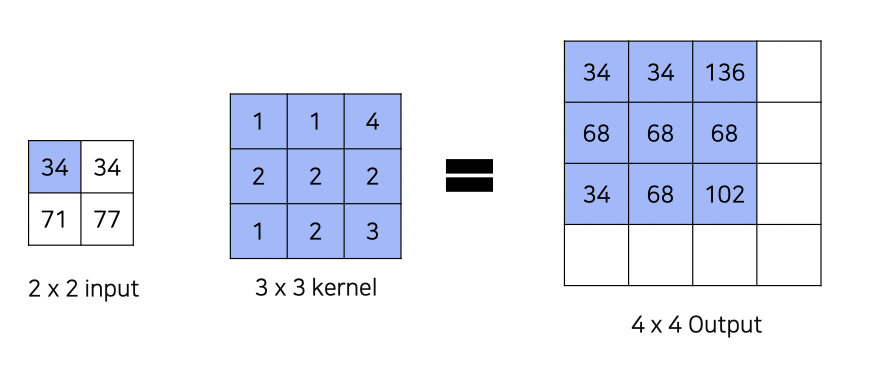
Transposed Convolution은 하나의 input pizel값을 kernel의 모든 pixel에 곱해 output을 구한다.
이때 겹치는 부분값은 전부 합해진다.
이런 Transpose Convolution을 통해 효과적인 Upsmapling이 가능해진다.
더군다나 Transpose Conv 도 Convolution중 하나이기 때문에 kernel이 학습 가능하다는 장점이 있다.
Upsampling은 FCN에서 중요한 과정중 하나이다.
FCN Architecture

기본적인 구조는 위와 같다.
Conv : Conolution - Batch Normalization - RELU Block
Pooling : Max Pooling , Resolution 1/2배
모델에서 Pooling을 여러번 반복하다 보니 기존 이미지의 resolution의 총 1/32($2^5$)배가 된다.
여기서 마지막 단계에서 Upsampling 32배를 다시 해주면 output의 resolution이 맞게 된다.
!!!!!!!
FCN은 성능을 향상시키기 위해, 한가지 트릭을 더 사용헀는데,
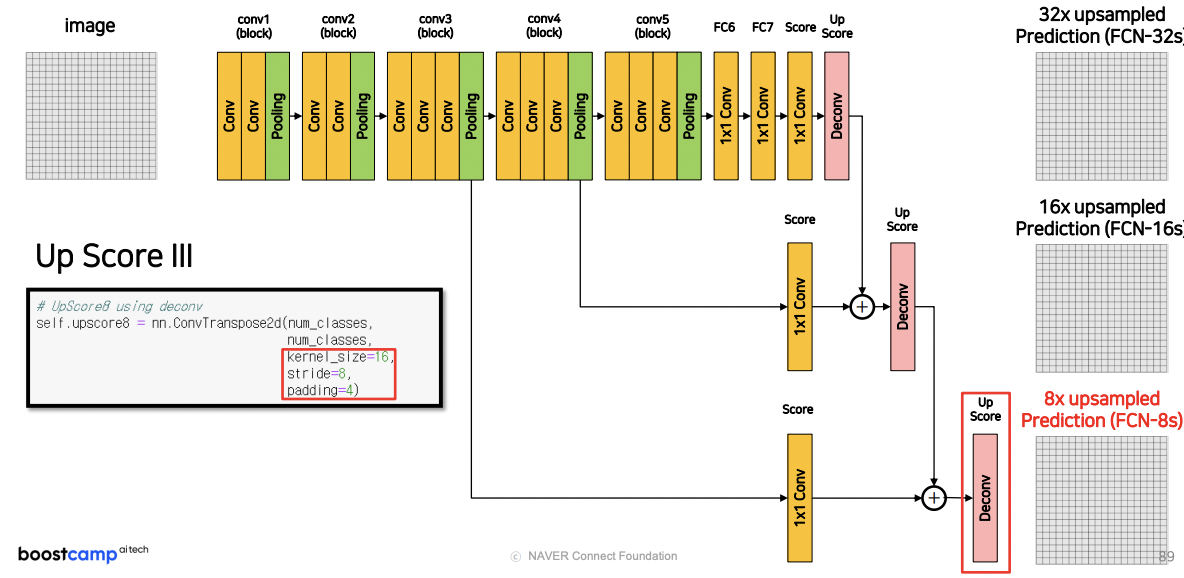
각 단계에서 추출한 feature map을 각각 독립적으로 transpose convolution을 해서 input image의 resolution으로 맞춘후,
하나로 합친다.
이 경우 다양한 단계에서의 feature map의 정보를 포함하고 있기 때문에 정보가 더 많아지고 정확도가 올라간다.

실제로 FCN-8s가 훨씬 디테일한 결과를 출력함을 알 수 있다.
'2021 네이버 부스트캠프 - Ai tech' 카테고리의 다른 글
| Week 11/12/13 - Semantic Segmentation - DeconvNet (0) | 2021.12.15 |
|---|---|
| Week 11/12/13 - Semantic Segmentation - FCN 한계점 (0) | 2021.12.15 |
| Week 11/12/13 - What is Semantic Segmentation? (0) | 2021.12.15 |
| Week 11/12/13 Level2- P Stage [Semantic Segmentation] (0) | 2021.11.19 |
| Week 8/9/10 - Object Detection - EfficientDet (0) | 2021.11.08 |