DeconvNet은 Deconvolution과정이 빈약해서 생기는 FCN의 한계점들을 보완하는 모델이다.
DeconvNet.
이름에서 알 수 있듯이 Deconvolution과정에 힘을 준 모델이다.
Architecture
Decoder를 Encoder와 대칭으로 만든 형태

Conv BLock이
VGG16를 사용해, [ Conv - BN - ReLU ] x 2 - Max Pooling의 과정을 거친다.
Deconvoliution Block은 정확히 반대순서로 간다.
UnPooling - [ Transpose Conv - BN - ReLU ] x 2
Unpooling과 Deconvolution을 동시에 반복적으로 사용하는 방법의 장점은 아래와 같다.
1. Unpooling은 디테일한 경계 포착
2. Transpose Conv은 전반적인 모습 포착
Unpooling
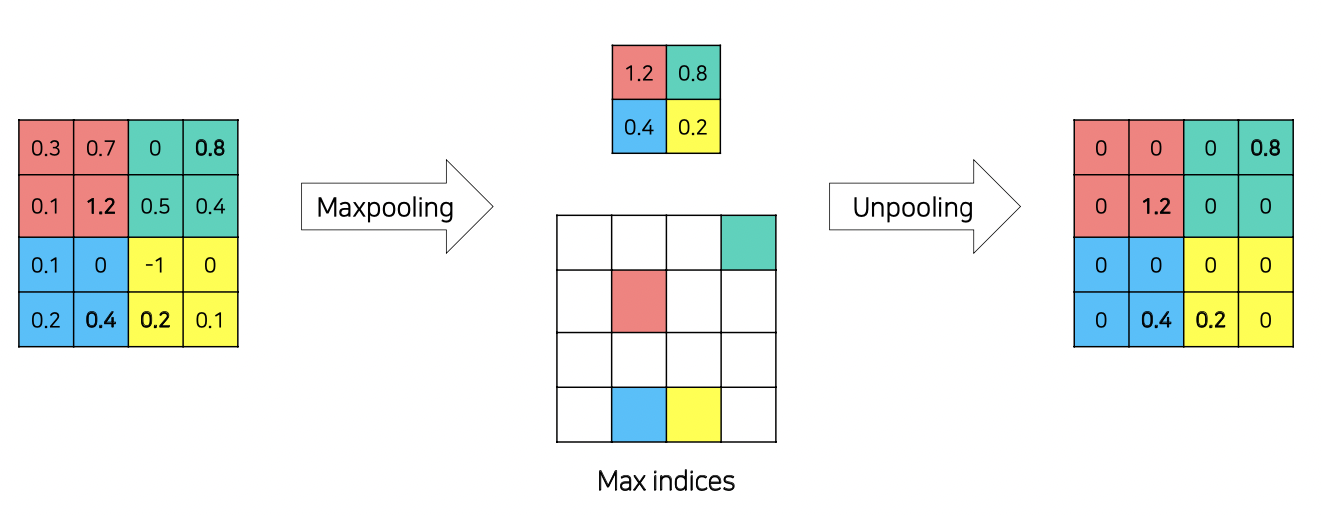
Max Pooling을 할때 그 위치 index를 기억해 놓았다 후에 해당 위치에 원래값을 복원하는것, 나머지는 0
- Pooling이 된 부분의 값만을 포함하기 때문에 결과로 대부분이 0인 Sparse Matrix가 나온다.
- 학습 불필요. Fast
Unpooling을 하면 Pooling과정에서 날라간 정보들을 어느정도 복원할 수 있다.
하지만 결과로 0이 대부분인 sparse matrix가 나오고 불충분한 느낌이 있다!!
따라서 Deconvolution을 추가적으로 수행해 나머지 빈칸들을 채워준다.
디테일한 Deconv 과정 완성~~~!

b부터 차례대로 Transposed Conv - Unpool - Transposed COnv - Unpool....의 순서다.
Unpooling( c,e,g...)를 보면 자세한 구조, 틀을 잡는다.
Trasnpose Conv은 잡힌 구조에 빈 부분을 채워넣는 모습을 볼 수 있다.

결론적으로 일반 FCN 보다 DeconvNet이 훨씬 뚜렷한 결과를 갖는다.
'2021 네이버 부스트캠프 - Ai tech' 카테고리의 다른 글
| Week 11/12/13 - Semantic Segmentation - PSP2Net (0) | 2021.12.16 |
|---|---|
| Week 11/12/13 - Semantic Segmentation - DeepLab v1 (0) | 2021.12.15 |
| Week 11/12/13 - Semantic Segmentation - FCN 한계점 (0) | 2021.12.15 |
| Week 11/12/13 - Semantic Segmentation - FCN (0) | 2021.12.15 |
| Week 11/12/13 - What is Semantic Segmentation? (0) | 2021.12.15 |